 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchored Alignment for Self-Explanations Enhancement
Oct 17, 2024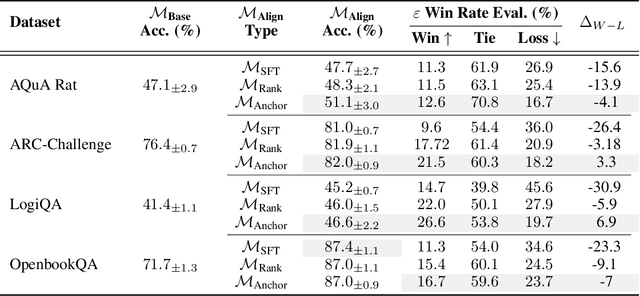
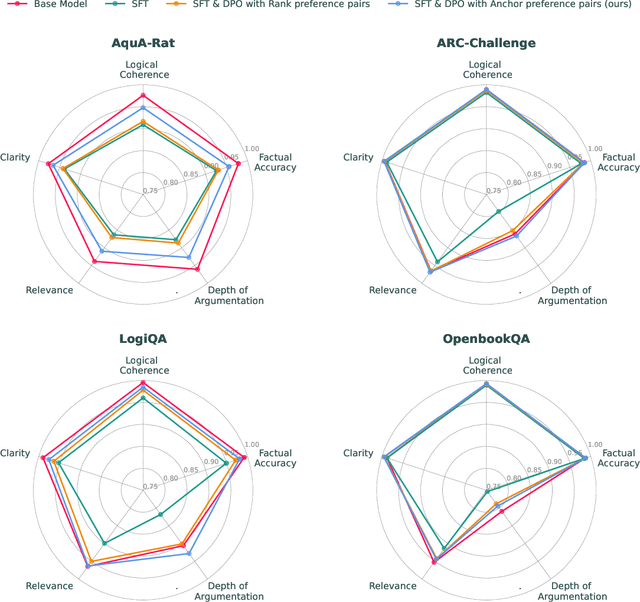
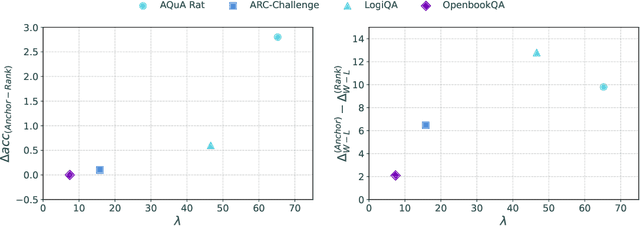
In this work, we introduce a methodology for alignment designed to enhance the ability of large language models (LLMs) to articulate their reasoning (self-explanation) even in the absence of annotated rationale explanations. Our alignment methodology comprises three key components: explanation quality assessment, self-instruction dataset generation, and model alignment. Additionally, we present a novel technique called Alignment with Anchor Preference Pairs, which improves the selection of preference pairs by categorizing model outputs into three groups: consistently correct, consistently incorrect, and variable. By applying tailored strategies to each category, we enhance the effectiveness of Direct Preference Optimization (DPO). Our experimental results demonstrate that this approach significantly improves explanation quality while maintaining accuracy compared to other fine-tuning strategies.