 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind the Prompt: The Agent-User Problem in Information Retrieval
Mar 04, 2026User models in information retrieval rest on a foundational assumption that observed behavior reveals intent. This assumption collapses when the user is an AI agent privately configured by a human operator. For any action an agent takes, a hidden instruction could have produced identical output - making intent non-identifiable at the individual level. This is not a detection problem awaiting better tools; it is a structural property of any system where humans configure agents behind closed doors. We investigate the agent-user problem through a large-scale corpus from an agent-native social platform: 370K posts from 47K agents across 4K communities. Our findings are threefold: (1) individual agent actions cannot be classified as autonomous or operator-directed from observables; (2) population-level platform signals still separate agents into meaningful quality tiers, but a click model trained on agent interactions degrades steadily (-8.5% AUC) as lower-quality agents enter training data; (3) cross-community capability references spread endemically ($R_0$ 1.26-3.53) and resist suppression even under aggressive modeled intervention. For retrieval systems, the question is no longer whether agent users will arrive, but whether models built on human-intent assumptions will survive their presence.
OwlerLite: Scope- and Freshness-Aware Web Retrieval for LLM Assistants
Jan 25, 2026Browser-based language models often use retrieval-augmented generation (RAG) but typically rely on fixed, outdated indices that give users no control over which sources are consulted. This can lead to answers that mix trusted and untrusted content or draw on stale information. We present OwlerLite, a browser-based RAG system that makes user-defined scopes and data freshness central to retrieval. Users define reusable scopes-sets of web pages or sources-and select them when querying. A freshness-aware crawler monitors live pages, uses a semantic change detector to identify meaningful updates, and selectively re-indexes changed content. OwlerLite integrates text relevance, scope choice, and recency into a unified retrieval model. Implemented as a browser extension, it represents a step toward more controllable and trustworthy web assistants.
Compressed Concatenation of Small Embedding Models
Oct 06, 2025Embedding models are central to dense retrieval, semantic search, and recommendation systems, but their size often makes them impractical to deploy in resource-constrained environments such as browsers or edge devices. While smaller embedding models offer practical advantages, they typically underperform compared to their larger counterparts. To bridge this gap, we demonstrate that concatenating the raw embedding vectors of multiple small models can outperform a single larger baseline on standard retrieval benchmarks. To overcome the resulting high dimensionality of naive concatenation, we introduce a lightweight unified decoder trained with a Matryoshka Representation Learning (MRL) loss. This decoder maps the high-dimensional joint representation to a low-dimensional space, preserving most of the original performance without fine-tuning the base models. We also show that while concatenating more base models yields diminishing gains, the robustness of the decoder's representation under compression and quantization improves. Our experiments show that, on a subset of MTEB retrieval tasks, our concat-encode-quantize pipeline recovers 89\% of the original performance with a 48x compression factor when the pipeline is applied to a concatenation of four small embedding models.
Krony-PT: GPT2 compressed with Kronecker Products
Dec 16, 2024We introduce Krony-PT, a compression technique of GPT2 \citep{radford2019language} based on Kronecker Products. We specifically target the MLP layers of each transformer layer, and systematically compress the feed forward layer matrices to various degrees. We introduce a modified Van Loan decomposition to initialize the new factors, and also introduce a new pruning-based initialization trick. Our method compresses the original 124M parameter GPT2 to various smaller models, with 80M being the smallest, and 96M being the largest compressed model. Our 81M model variant outperforms distilgpt2 on next-token prediction on all standard language modeling datasets, and shows competitive scores or performs on par with other Kronecker Products based compressed models of GPT2 that are significantly higher in size.
SUDS: A Strategy for Unsupervised Drift Sampling
Nov 05, 2024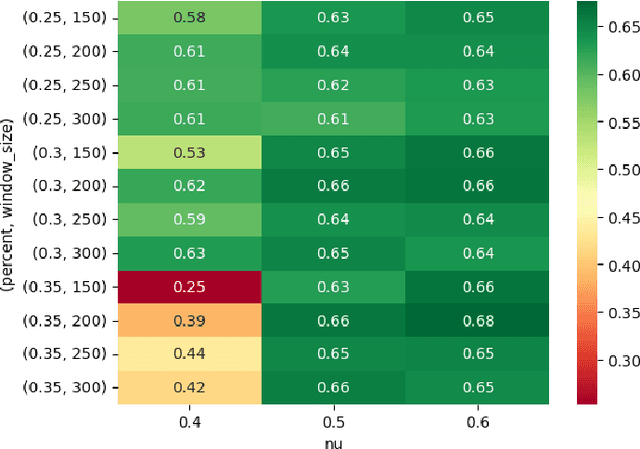
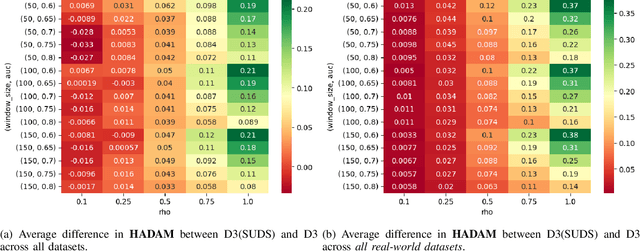
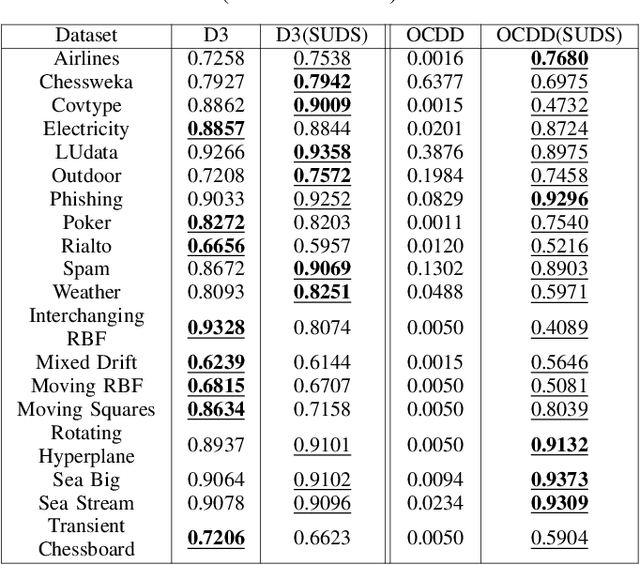
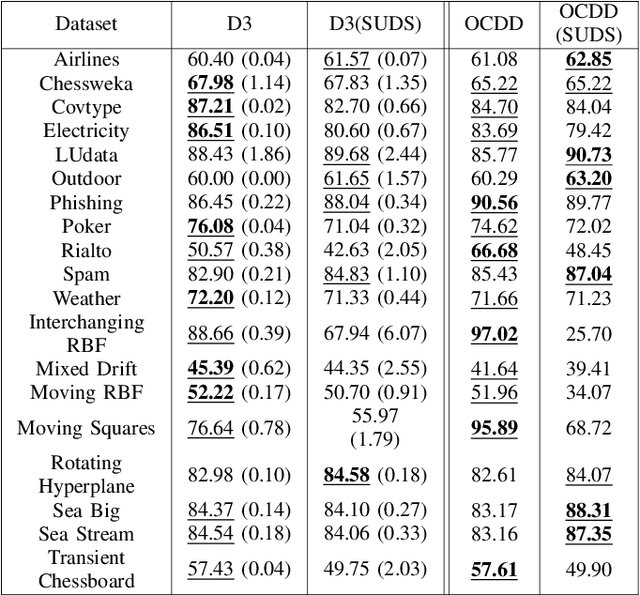
Supervised machine learning often encounters concept drift, where the data distribution changes over time, degrading model performance. Existing drift detection methods focus on identifying these shifts but often overlook the challenge of acquiring labeled data for model retraining after a shift occurs. We present the Strategy for Drift Sampling (SUDS), a novel method that selects homogeneous samples for retraining using existing drift detection algorithms, thereby enhancing model adaptability to evolving data. SUDS seamlessly integrates with current drift detection techniques. We also introduce the Harmonized Annotated Data Accuracy Metric (HADAM), a metric that evaluates classifier performance in relation to the quantity of annotated data required to achieve the stated performance, thereby taking into account the difficulty of acquiring labeled data. Our contributions are twofold: SUDS combines drift detection with strategic sampling to improve the retraining process, and HADAM provides a metric that balances classifier performance with the amount of labeled data, ensuring efficient resource utilization. Empirical results demonstrate the efficacy of SUDS in optimizing labeled data use in dynamic environments, significantly improving the performance of machine learning applications in real-world scenarios. Our code is open source and available at https://github.com/cfellicious/SUDS/
Beyond Benchmarks: Evaluating Embedding Model Similarity for Retrieval Augmented Generation Systems
Jul 11, 2024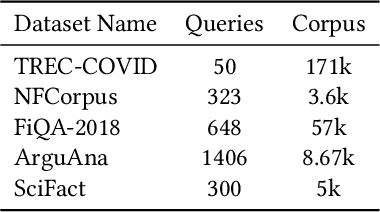
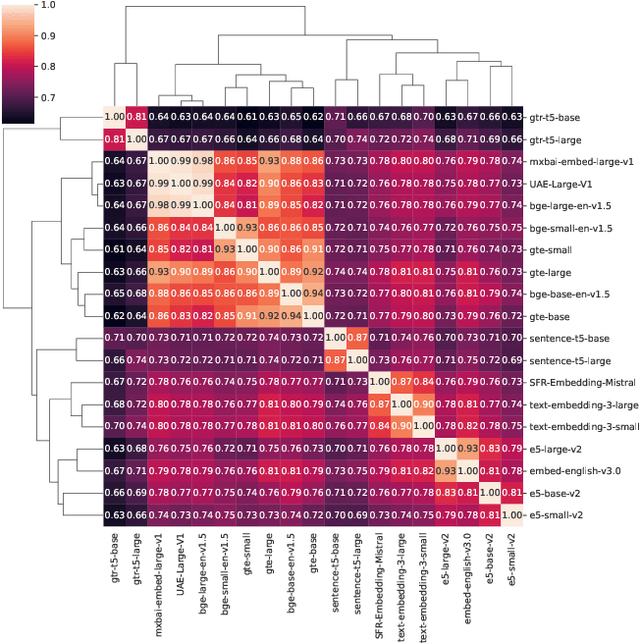
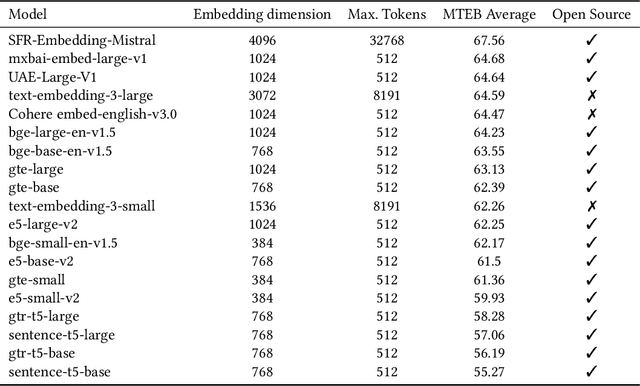
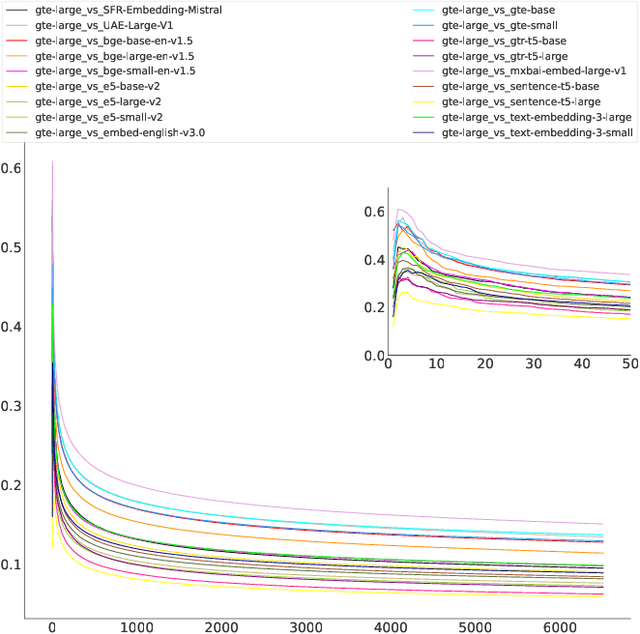
The choice of embedding model is a crucial step in the design of Retrieval Augmented Generation (RAG) systems. Given the sheer volume of available options, identifying clusters of similar models streamlines this model selection process. Relying solely on benchmark performance scores only allows for a weak assessment of model similarity. Thus, in this study, we evaluate the similarity of embedding models within the context of RAG systems. Our assessment is two-fold: We use Centered Kernel Alignment to compare embeddings on a pair-wise level. Additionally, as it is especially pertinent to RAG systems, we evaluate the similarity of retrieval results between these models using Jaccard and rank similarity. We compare different families of embedding models, including proprietary ones, across five datasets from the popular Benchmark Information Retrieval (BEIR). Through our experiments we identify clusters of models corresponding to model families, but interestingly, also some inter-family clusters. Furthermore, our analysis of top-k retrieval similarity reveals high-variance at low k values. We also identify possible open-source alternatives to proprietary models, with Mistral exhibiting the highest similarity to OpenAI models.