 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Semantic Gap in Virtual Machine Introspection and Forensic Memory Analysis
Mar 07, 2025



Forensic Memory Analysis (FMA) and Virtual Machine Introspection (VMI) are critical tools for security in a virtualization-based approach. VMI and FMA involves using digital forensic methods to extract information from the system to identify and explain security incidents. A key challenge in both FMA and VMI is the "Semantic Gap", which is the difficulty of interpreting raw memory data without specialized tools and expertise. In this work, we investigate how a priori knowledge, metadata and engineered features can aid VMI and FMA, leveraging machine learning to automate information extraction and reduce the workload of forensic investigators. We choose OpenSSH as our use case to test different methods to extract high level structures. We also test our method on complete physical memory dumps to showcase the effectiveness of the engineered features. Our features range from basic statistical features to advanced graph-based representations using malloc headers and pointer translations. The training and testing are carried out on public datasets that we compare against already recognized baseline methods. We show that using metadata, we can improve the performance of the algorithm when there is very little training data and also quantify how having more data results in better generalization performance. The final contribution is an open dataset of physical memory dumps, totalling more than 1 TB of different memory state, software environments, main memory capacities and operating system versions. Our methods show that having more metadata boosts performance with all methods obtaining an F1-Score of over 80%. Our research underscores the possibility of using feature engineering and machine learning techniques to bridge the semantic gap.
Malware Detection based on API calls
Feb 18, 2025



Malware attacks pose a significant threat in today's interconnected digital landscape, causing billions of dollars in damages. Detecting and identifying families as early as possible provides an edge in protecting against such malware. We explore a lightweight, order-invariant approach to detecting and mitigating malware threats: analyzing API calls without regard to their sequence. We publish a public dataset of over three hundred thousand samples and their function call parameters for this task, annotated with labels indicating benign or malicious activity. The complete dataset is above 550GB uncompressed in size. We leverage machine learning algorithms, such as random forests, and conduct behavioral analysis by examining patterns and anomalies in API call sequences. By investigating how the function calls occur regardless of their order, we can identify discriminating features that can help us identify malware early on. The models we've developed are not only effective but also efficient. They are lightweight and can run on any machine with minimal performance overhead, while still achieving an impressive F1-Score of over 85\%. We also empirically show that we only need a subset of the function call sequence, specifically calls to the ntdll.dll library, to identify malware. Our research demonstrates the efficacy of this approach through empirical evaluations, underscoring its accuracy and scalability. The code is open source and available at Github along with the dataset on Zenodo.
On the Suitability of pre-trained foundational LLMs for Analysis in German Legal Education
Dec 20, 2024We show that current open-source foundational LLMs possess instruction capability and German legal background knowledge that is sufficient for some legal analysis in an educational context. However, model capability breaks down in very specific tasks, such as the classification of "Gutachtenstil" appraisal style components, or with complex contexts, such as complete legal opinions. Even with extended context and effective prompting strategies, they cannot match the Bag-of-Words baseline. To combat this, we introduce a Retrieval Augmented Generation based prompt example selection method that substantially improves predictions in high data availability scenarios. We further evaluate the performance of pre-trained LLMs on two standard tasks for argument mining and automated essay scoring and find it to be more adequate. Throughout, pre-trained LLMs improve upon the baseline in scenarios with little or no labeled data with Chain-of-Thought prompting further helping in the zero-shot case.
SUDS: A Strategy for Unsupervised Drift Sampling
Nov 05, 2024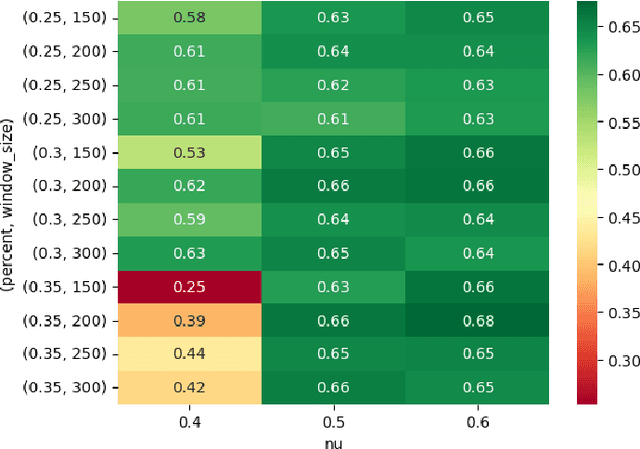
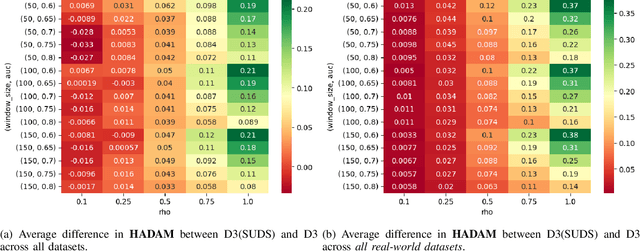
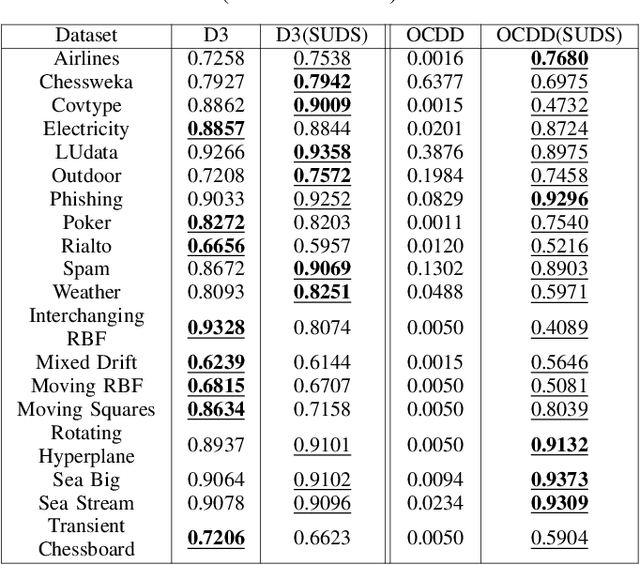
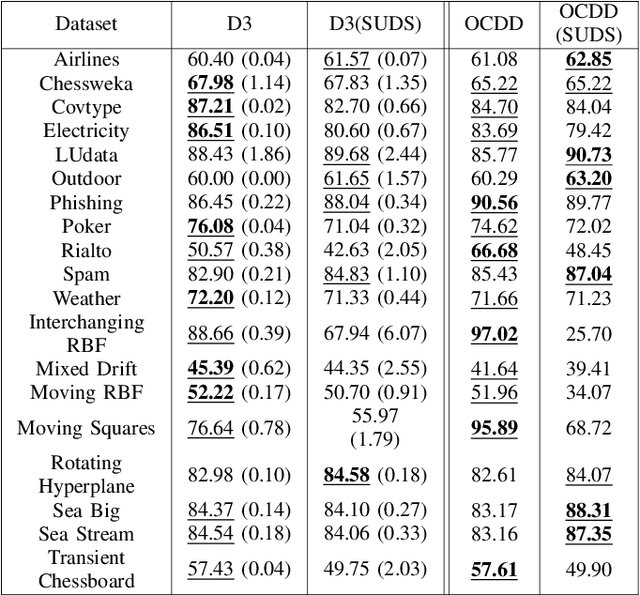
Supervised machine learning often encounters concept drift, where the data distribution changes over time, degrading model performance. Existing drift detection methods focus on identifying these shifts but often overlook the challenge of acquiring labeled data for model retraining after a shift occurs. We present the Strategy for Drift Sampling (SUDS), a novel method that selects homogeneous samples for retraining using existing drift detection algorithms, thereby enhancing model adaptability to evolving data. SUDS seamlessly integrates with current drift detection techniques. We also introduce the Harmonized Annotated Data Accuracy Metric (HADAM), a metric that evaluates classifier performance in relation to the quantity of annotated data required to achieve the stated performance, thereby taking into account the difficulty of acquiring labeled data. Our contributions are twofold: SUDS combines drift detection with strategic sampling to improve the retraining process, and HADAM provides a metric that balances classifier performance with the amount of labeled data, ensuring efficient resource utilization. Empirical results demonstrate the efficacy of SUDS in optimizing labeled data use in dynamic environments, significantly improving the performance of machine learning applications in real-world scenarios. Our code is open source and available at https://github.com/cfellicious/SUDS/
DriftGAN: Using historical data for Unsupervised Recurring Drift Detection
Jul 09, 2024In real-world applications, input data distributions are rarely static over a period of time, a phenomenon known as concept drift. Such concept drifts degrade the model's prediction performance, and therefore we require methods to overcome these issues. The initial step is to identify concept drifts and have a training method in place to recover the model's performance. Most concept drift detection methods work on detecting concept drifts and signalling the requirement to retrain the model. However, in real-world cases, there could be concept drifts that recur over a period of time. In this paper, we present an unsupervised method based on Generative Adversarial Networks(GAN) to detect concept drifts and identify whether a specific concept drift occurred in the past. Our method reduces the time and data the model requires to get up to speed for recurring drifts. Our key results indicate that our proposed model can outperform the current state-of-the-art models in most datasets. We also test our method on a real-world use case from astrophysics, where we detect the bow shock and magnetopause crossings with better results than the existing methods in the domain.
SmartKex: Machine Learning Assisted SSH Keys Extraction From The Heap Dump
Sep 13, 2022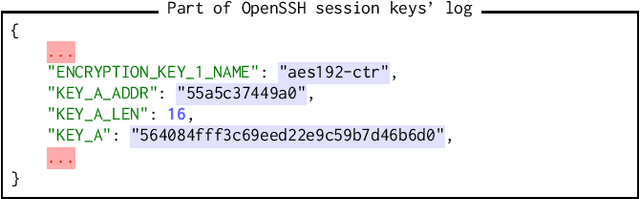

Digital forensics is the process of extracting, preserving, and documenting evidence in digital devices. A commonly used method in digital forensics is to extract data from the main memory of a digital device. However, the main challenge is identifying the important data to be extracted. Several pieces of crucial information reside in the main memory, like usernames, passwords, and cryptographic keys such as SSH session keys. In this paper, we propose SmartKex, a machine-learning assisted method to extract session keys from heap memory snapshots of an OpenSSH process. In addition, we release an openly available dataset and the corresponding toolchain for creating additional data. Finally, we compare SmartKex with naive brute-force methods and empirically show that SmartKex can extract the session keys with high accuracy and high throughput. With the provided resources, we intend to strengthen the research on the intersection between digital forensics, cybersecurity, and machine learning.
Transfer Learning and Organic Computing for Autonomous Vehicles
Aug 16, 2018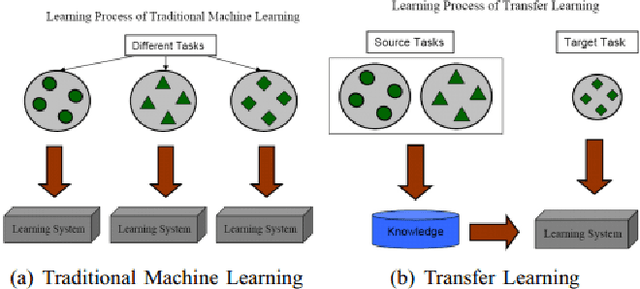
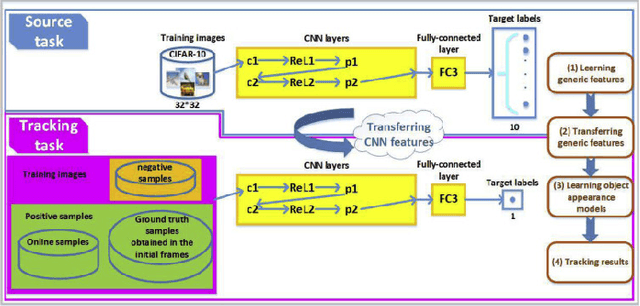
Autonomous Vehicles(AV) are one of the brightest promises of the future which would help cut down fatalities and improve travel time while working in harmony. Autonomous vehicles will face with challenging situations and experiences not seen before. These experiences should be converted to knowledge and help the vehicle prepare better in the future. Online Transfer Learning will help transferring prior knowledge to a new task and also keep the knowledge updated as the task evolves. This paper presents the different methods of transfer learning, online transfer learning and organic computing that could be adapted to the domain of autonomous vehicles.