 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUDS: A Strategy for Unsupervised Drift Sampling
Nov 05, 2024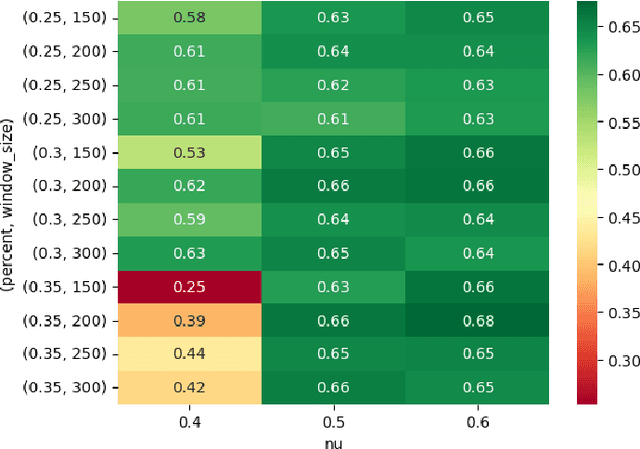
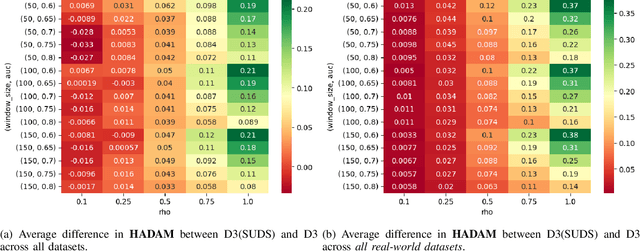
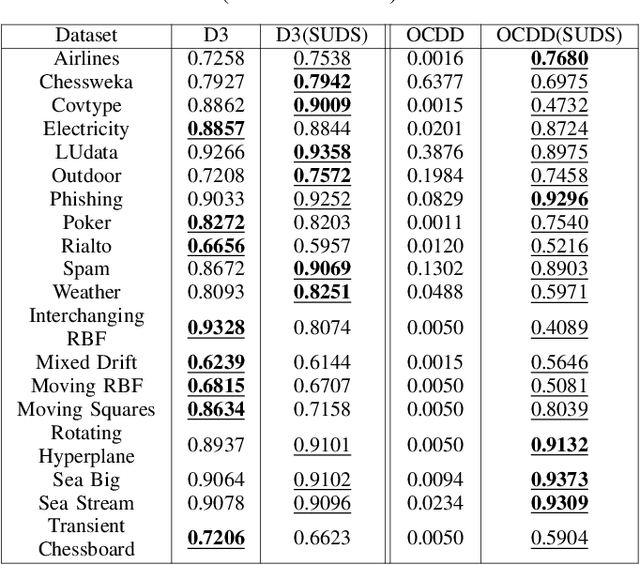
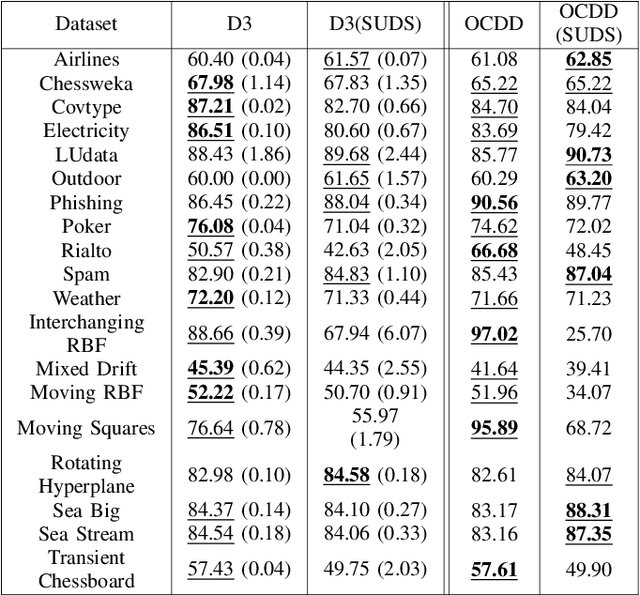
Supervised machine learning often encounters concept drift, where the data distribution changes over time, degrading model performance. Existing drift detection methods focus on identifying these shifts but often overlook the challenge of acquiring labeled data for model retraining after a shift occurs. We present the Strategy for Drift Sampling (SUDS), a novel method that selects homogeneous samples for retraining using existing drift detection algorithms, thereby enhancing model adaptability to evolving data. SUDS seamlessly integrates with current drift detection techniques. We also introduce the Harmonized Annotated Data Accuracy Metric (HADAM), a metric that evaluates classifier performance in relation to the quantity of annotated data required to achieve the stated performance, thereby taking into account the difficulty of acquiring labeled data. Our contributions are twofold: SUDS combines drift detection with strategic sampling to improve the retraining process, and HADAM provides a metric that balances classifier performance with the amount of labeled data, ensuring efficient resource utilization. Empirical results demonstrate the efficacy of SUDS in optimizing labeled data use in dynamic environments, significantly improving the performance of machine learning applications in real-world scenarios. Our code is open source and available at https://github.com/cfellicious/SUDS/