 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Credit Card Fraud Detection: A Journey from Research to Production
Jul 20, 2021
The dark face of digital commerce generalization is the increase of fraud attempts. To prevent any type of attacks, state of the art fraud detection systems are now embedding Machine Learning (ML) modules. The conception of such modules is only communicated at the level of research and papers mostly focus on results for isolated benchmark datasets and metrics. But research is only a part of the journey, preceded by the right formulation of the business problem and collection of data, and followed by a practical integration. In this paper, we give a wider vision of the process, on a case study of transfer learning for fraud detection, from business to research, and back to business.
A Constrained Randomized Shortest-Paths Framework for Optimal Exploration
Jul 12, 2018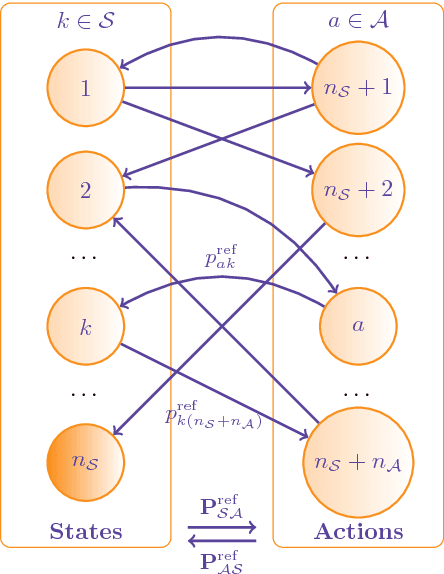
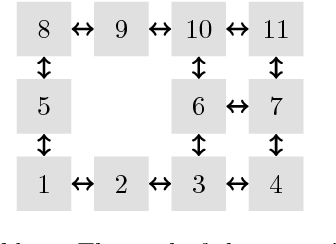
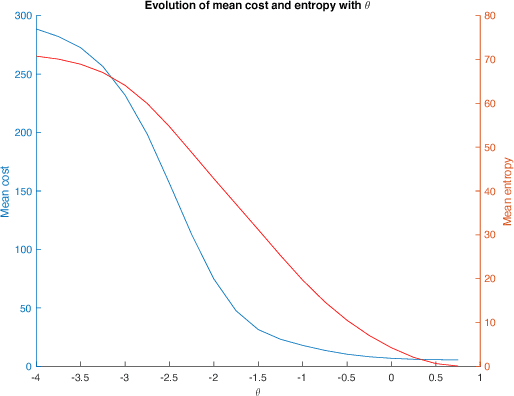
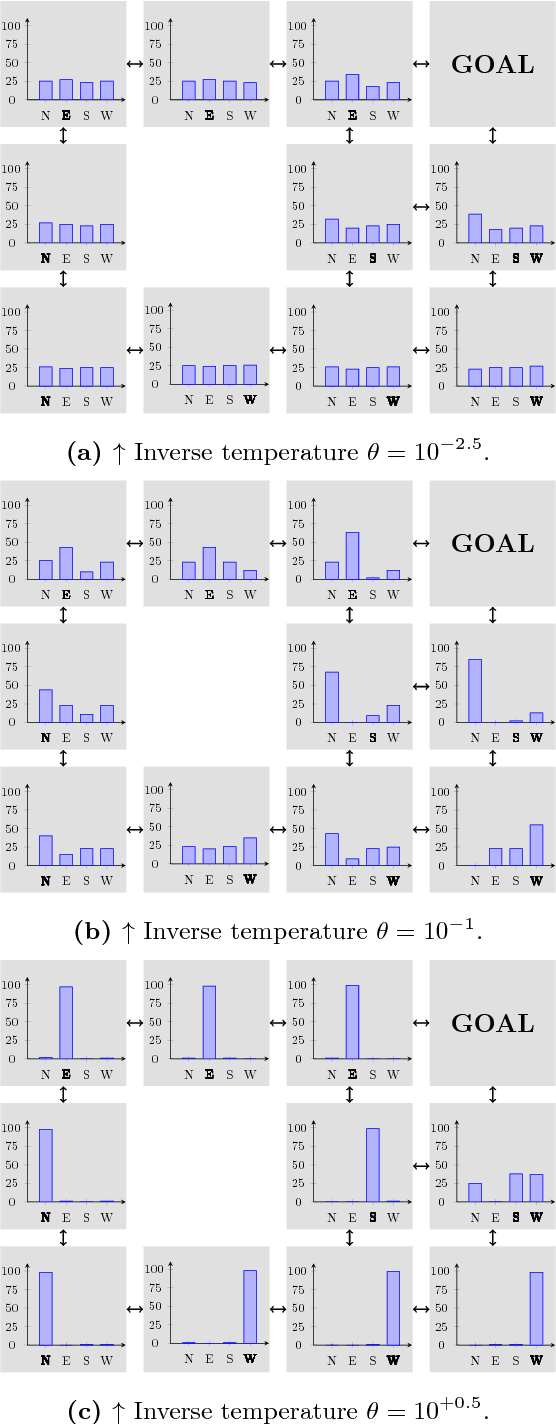
The present work extends the randomized shortest-paths framework (RSP), interpolating between shortest-path and random-walk routing in a network, in three directions. First, it shows how to deal with equality constraints on a subset of transition probabilities and develops a generic algorithm for solving this constrained RSP problem using Lagrangian duality. Second, it derives a surprisingly simple iterative procedure to compute the optimal, randomized, routing policy generalizing the previously developed "soft" Bellman-Ford algorithm. The resulting algorithm allows balancing exploitation and exploration in an optimal way by interpolating between a pure random behavior and the deterministic, optimal, policy (least-cost paths) while satisfying the constraints. Finally, the two algorithms are applied to Markov decision problems by considering the process as a constrained RSP on a bipartite state-action graph. In this context, the derived "soft" value iteration algorithm appears to be closely related to dynamic policy programming as well as Kullback-Leibler and path integral control, and similar to a recently introduced reinforcement learning exploration strategy. This shows that this strategy is optimal in the RSP sense - it minimizes expected path cost subject to relative entropy constraint. Simulation results on illustrative examples show that the model behaves as expected.
An experimental study of graph-based semi-supervised classification with additional node information
May 24, 2017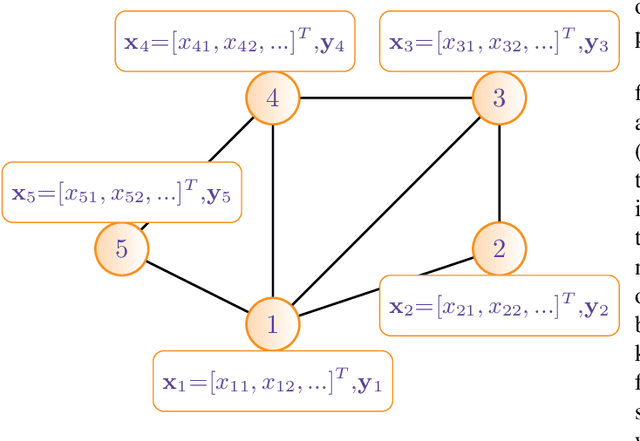
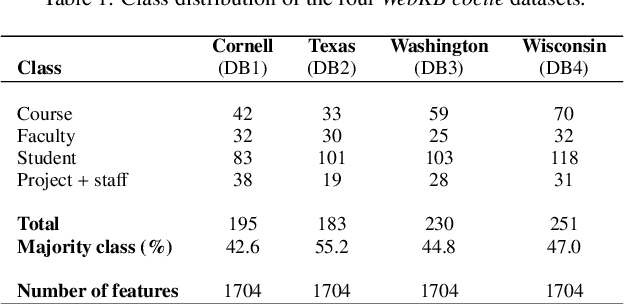
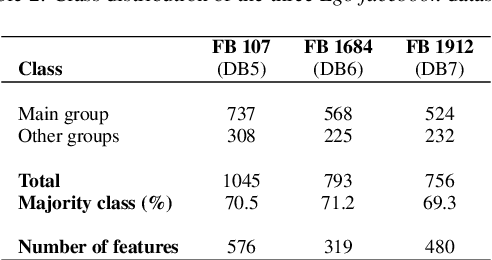
The volume of data generated by internet and social networks is increasing every day, and there is a clear need for efficient ways of extracting useful information from them. As those data can take different forms, it is important to use all the available data representations for prediction. In this paper, we focus our attention on supervised classification using both regular plain, tabular, data and structural information coming from a network structure. 14 techniques are investigated and compared in this study and can be divided in three classes: the first one uses only the plain data to build a classification model, the second uses only the graph structure and the last uses both information sources. The relative performances in these three cases are investigated. Furthermore, the effect of using a graph embedding and well-known indicators in spatial statistics is also studied. Possible applications are automatic classification of web pages or other linked documents, of people in a social network or of proteins in a biological complex system, to name a few. Based on our comparison, we draw some general conclusions and advices to tackle this particular classification task: some datasets can be better explained by their graph structure (graph-driven), or by their feature set (features-driven). The most efficient methods are discussed in both cases.
Semi-Supervised Classification Through the Bag-of-Paths Group Betweenness
Oct 16, 2012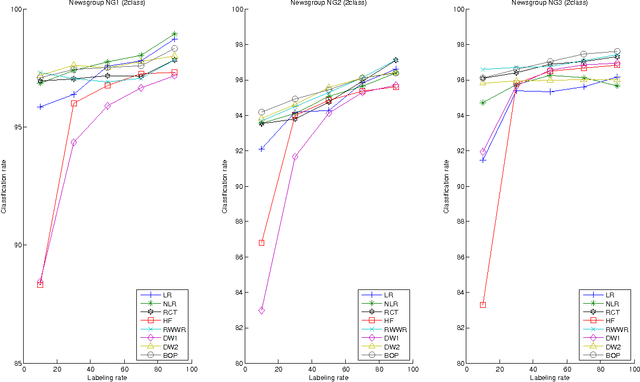
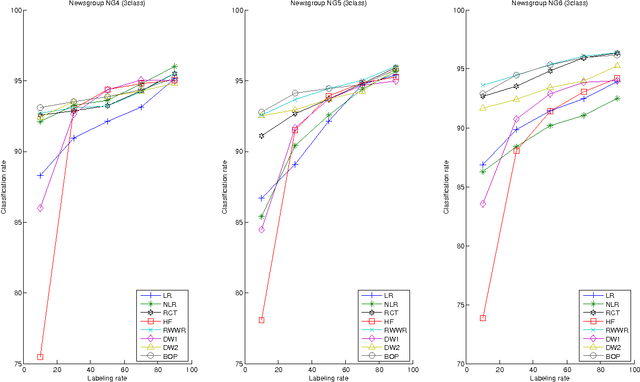
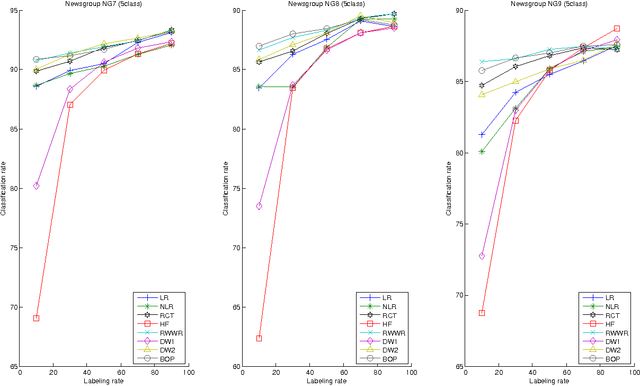
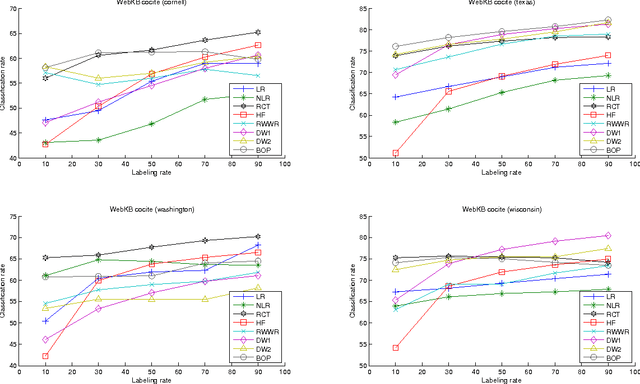
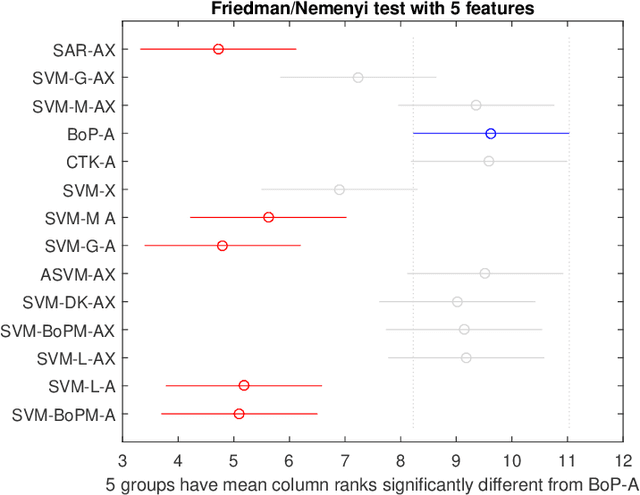
This paper introduces a novel, well-founded, betweenness measure, called the Bag-of-Paths (BoP) betweenness, as well as its extension, the BoP group betweenness, to tackle semisupervised classification problems on weighted directed graphs. The objective of semi-supervised classification is to assign a label to unlabeled nodes using the whole topology of the graph and the labeled nodes at our disposal. The BoP betweenness relies on a bag-of-paths framework assigning a Boltzmann distribution on the set of all possible paths through the network such that long (high-cost) paths have a low probability of being picked from the bag, while short (low-cost) paths have a high probability of being picked. Within that context, the BoP betweenness of node j is defined as the sum of the a posteriori probabilities that node j lies in-between two arbitrary nodes i, k, when picking a path starting in i and ending in k. Intuitively, a node typically receives a high betweenness if it has a large probability of appearing on paths connecting two arbitrary nodes of the network. This quantity can be computed in closed form by inverting a n x n matrix where n is the number of nodes. For the group betweenness, the paths are constrained to start and end in nodes within the same class, therefore defining a group betweenness for each class. Unlabeled nodes are then classified according to the class showing the highest group betweenness. Experiments on various real-world data sets show that BoP group betweenness outperforms all the tested state of-the-art methods. The benefit of the BoP betweenness is particularly noticeable when only a few labeled nodes are available.