 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn experimental study of graph-based semi-supervised classification with additional node information
Paper and Code
May 24, 2017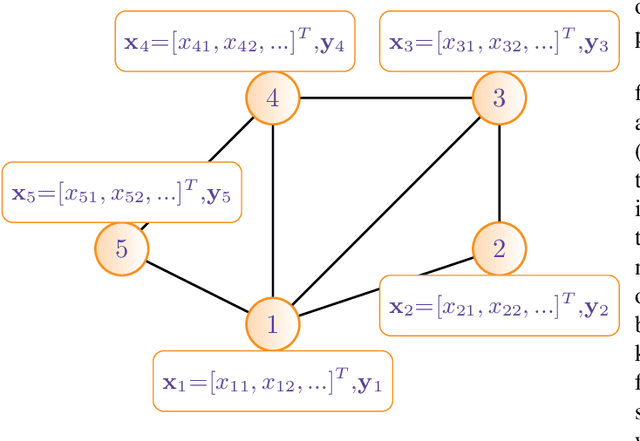
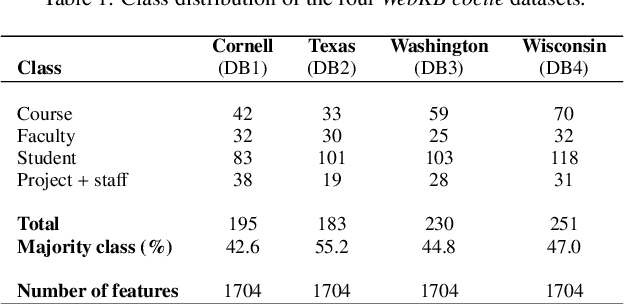
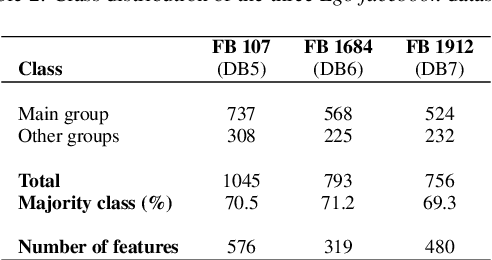
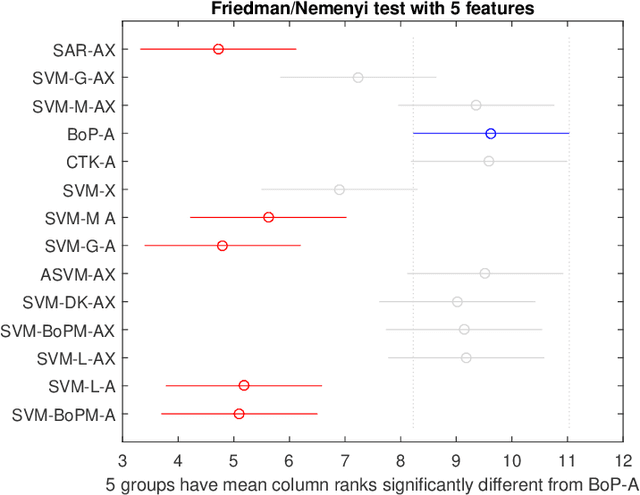
The volume of data generated by internet and social networks is increasing every day, and there is a clear need for efficient ways of extracting useful information from them. As those data can take different forms, it is important to use all the available data representations for prediction. In this paper, we focus our attention on supervised classification using both regular plain, tabular, data and structural information coming from a network structure. 14 techniques are investigated and compared in this study and can be divided in three classes: the first one uses only the plain data to build a classification model, the second uses only the graph structure and the last uses both information sources. The relative performances in these three cases are investigated. Furthermore, the effect of using a graph embedding and well-known indicators in spatial statistics is also studied. Possible applications are automatic classification of web pages or other linked documents, of people in a social network or of proteins in a biological complex system, to name a few. Based on our comparison, we draw some general conclusions and advices to tackle this particular classification task: some datasets can be better explained by their graph structure (graph-driven), or by their feature set (features-driven). The most efficient methods are discussed in both cases.