 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Model-Based Data Acquisition for Subjective Multi-Task NLP Problems
Dec 13, 2023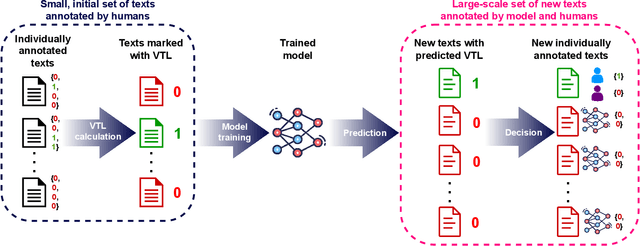
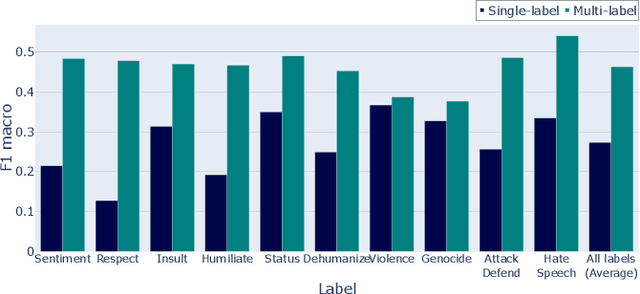
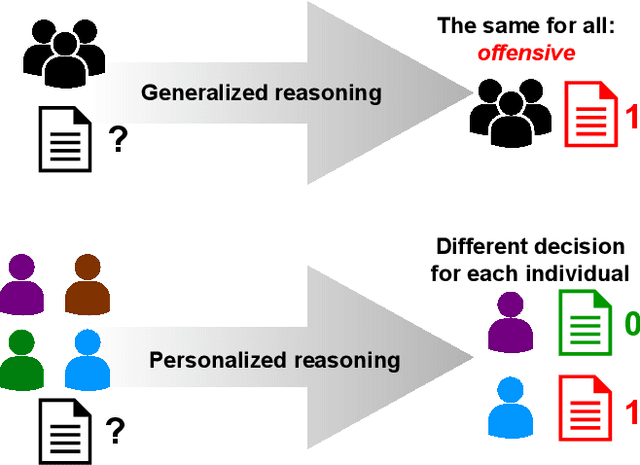
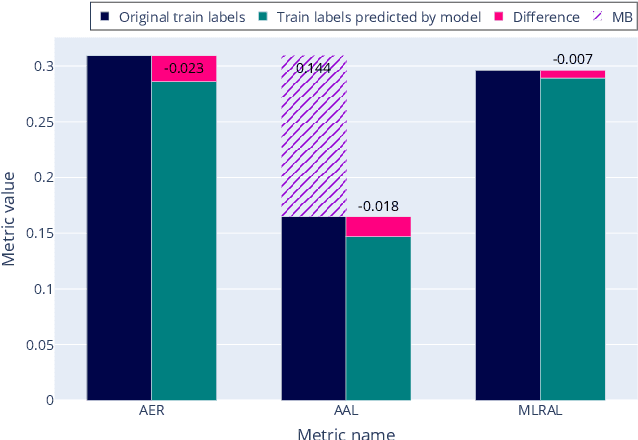
Data annotated by humans is a source of knowledge by describing the peculiarities of the problem and therefore fueling the decision process of the trained model. Unfortunately, the annotation process for subjective natural language processing (NLP) problems like offensiveness or emotion detection is often very expensive and time-consuming. One of the inevitable risks is to spend some of the funds and annotator effort on annotations that do not provide any additional knowledge about the specific task. To minimize these costs, we propose a new model-based approach that allows the selection of tasks annotated individually for each text in a multi-task scenario. The experiments carried out on three datasets, dozens of NLP tasks, and thousands of annotations show that our method allows up to 40% reduction in the number of annotations with negligible loss of knowledge. The results also emphasize the need to collect a diverse amount of data required to efficiently train a model, depending on the subjectivity of the annotation task. We also focused on measuring the relation between subjective tasks by evaluating the model in single-task and multi-task scenarios. Moreover, for some datasets, training only on the labels predicted by our model improved the efficiency of task selection as a self-supervised learning regularization technique.
ChatGPT: Jack of all trades, master of none
Feb 21, 2023



OpenAI has released the Chat Generative Pre-trained Transformer (ChatGPT) and revolutionized the approach in artificial intelligence to human-model interaction. The first contact with the chatbot reveals its ability to provide detailed and precise answers in various areas. There are several publications on ChatGPT evaluation, testing its effectiveness on well-known natural language processing (NLP) tasks. However, the existing studies are mostly non-automated and tested on a very limited scale. In this work, we examined ChatGPT's capabilities on 25 diverse analytical NLP tasks, most of them subjective even to humans, such as sentiment analysis, emotion recognition, offensiveness and stance detection, natural language inference, word sense disambiguation, linguistic acceptability and question answering. We automated ChatGPT's querying process and analyzed more than 38k responses. Our comparison of its results with available State-of-the-Art (SOTA) solutions showed that the average loss in quality of the ChatGPT model was about 25% for zero-shot and few-shot evaluation. We showed that the more difficult the task (lower SOTA performance), the higher the ChatGPT loss. It especially refers to pragmatic NLP problems like emotion recognition. We also tested the ability of personalizing ChatGPT responses for selected subjective tasks via Random Contextual Few-Shot Personalization, and we obtained significantly better user-based predictions. Additional qualitative analysis revealed a ChatGPT bias, most likely due to the rules imposed on human trainers by OpenAI. Our results provide the basis for a fundamental discussion of whether the high quality of recent predictive NLP models can indicate a tool's usefulness to society and how the learning and validation procedures for such systems should be established.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.