 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Generalized Laughter to Personalized Chuckles: Unleashing the Power of Data Fusion in Subjective Humor Detection
Dec 18, 2023The vast area of subjectivity in Natural Language Processing (NLP) poses a challenge to the solutions typically used in generalized tasks. As exploration in the scope of generalized NLP is much more advanced, it implies the tremendous gap that is still to be addressed amongst all feasible tasks where an opinion, taste, or feelings are inherent, thus creating a need for a solution, where a data fusion could take place. We have chosen the task of funniness, as it heavily relies on the sense of humor, which is fundamentally subjective. Our experiments across five personalized and four generalized datasets involving several personalized deep neural architectures have shown that the task of humor detection greatly benefits from the inclusion of personalized data in the training process. We tested five scenarios of training data fusion that focused on either generalized (majority voting) or personalized approaches to humor detection. The best results were obtained for the setup, in which all available personalized datasets were joined to train the personalized reasoning model. It boosted the prediction performance by up to approximately 35% of the macro F1 score. Such a significant gain was observed for all five personalized test sets. At the same time, the impact of the model's architecture was much less than the personalization itself. It seems that concatenating personalized datasets, even with the cost of normalizing the range of annotations across all datasets, if combined with the personalized models, results in an enormous increase in the performance of humor detection.
Towards Model-Based Data Acquisition for Subjective Multi-Task NLP Problems
Dec 13, 2023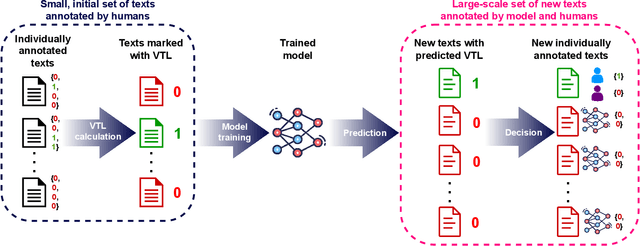
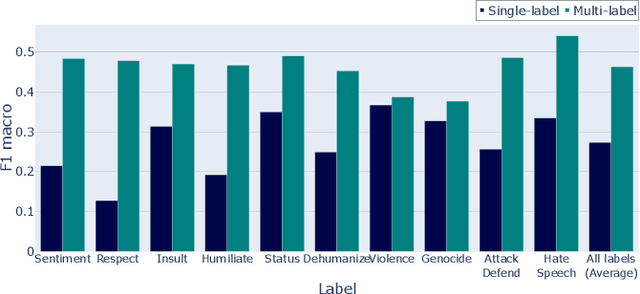
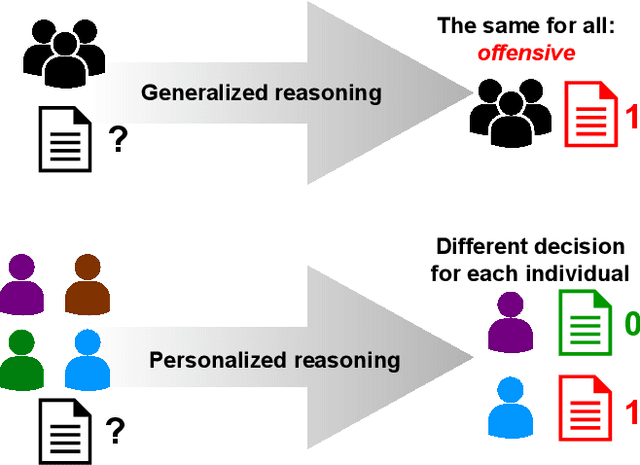
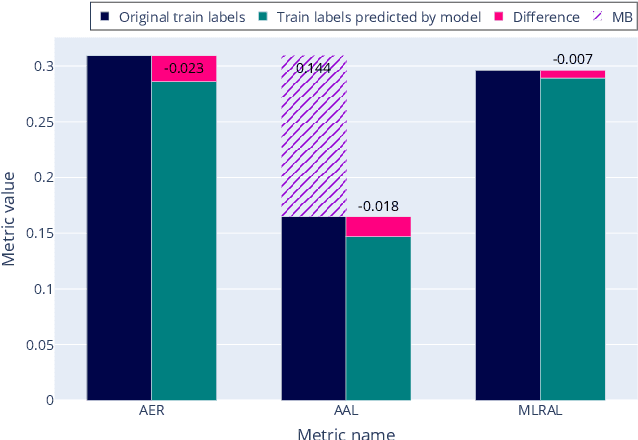
Data annotated by humans is a source of knowledge by describing the peculiarities of the problem and therefore fueling the decision process of the trained model. Unfortunately, the annotation process for subjective natural language processing (NLP) problems like offensiveness or emotion detection is often very expensive and time-consuming. One of the inevitable risks is to spend some of the funds and annotator effort on annotations that do not provide any additional knowledge about the specific task. To minimize these costs, we propose a new model-based approach that allows the selection of tasks annotated individually for each text in a multi-task scenario. The experiments carried out on three datasets, dozens of NLP tasks, and thousands of annotations show that our method allows up to 40% reduction in the number of annotations with negligible loss of knowledge. The results also emphasize the need to collect a diverse amount of data required to efficiently train a model, depending on the subjectivity of the annotation task. We also focused on measuring the relation between subjective tasks by evaluating the model in single-task and multi-task scenarios. Moreover, for some datasets, training only on the labels predicted by our model improved the efficiency of task selection as a self-supervised learning regularization technique.
ChatGPT: Jack of all trades, master of none
Feb 21, 2023



OpenAI has released the Chat Generative Pre-trained Transformer (ChatGPT) and revolutionized the approach in artificial intelligence to human-model interaction. The first contact with the chatbot reveals its ability to provide detailed and precise answers in various areas. There are several publications on ChatGPT evaluation, testing its effectiveness on well-known natural language processing (NLP) tasks. However, the existing studies are mostly non-automated and tested on a very limited scale. In this work, we examined ChatGPT's capabilities on 25 diverse analytical NLP tasks, most of them subjective even to humans, such as sentiment analysis, emotion recognition, offensiveness and stance detection, natural language inference, word sense disambiguation, linguistic acceptability and question answering. We automated ChatGPT's querying process and analyzed more than 38k responses. Our comparison of its results with available State-of-the-Art (SOTA) solutions showed that the average loss in quality of the ChatGPT model was about 25% for zero-shot and few-shot evaluation. We showed that the more difficult the task (lower SOTA performance), the higher the ChatGPT loss. It especially refers to pragmatic NLP problems like emotion recognition. We also tested the ability of personalizing ChatGPT responses for selected subjective tasks via Random Contextual Few-Shot Personalization, and we obtained significantly better user-based predictions. Additional qualitative analysis revealed a ChatGPT bias, most likely due to the rules imposed on human trainers by OpenAI. Our results provide the basis for a fundamental discussion of whether the high quality of recent predictive NLP models can indicate a tool's usefulness to society and how the learning and validation procedures for such systems should be established.