 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrySQL: text-to-SQL training with retry data for self-correcting query generation
Jul 03, 2025The text-to-SQL task is an active challenge in Natural Language Processing. Many existing solutions focus on using black-box language models extended with specialized components within customized end-to-end text-to-SQL pipelines. While these solutions use both closed-source proprietary language models and coding-oriented open-source models, there is a lack of research regarding SQL-specific generative models. At the same time, recent advancements in self-correcting generation strategies show promise for improving the capabilities of existing architectures. The application of these concepts to the text-to-SQL task remains unexplored. In this paper, we introduce RetrySQL, a new approach to training text-to-SQL generation models. We prepare reasoning steps for reference SQL queries and then corrupt them to create retry data that contains both incorrect and corrected steps, divided with a special token. We continuously pre-train an open-source coding model with this data and demonstrate that retry steps yield an improvement of up to 4 percentage points in both overall and challenging execution accuracy metrics, compared to pre-training without retry data. Additionally, we confirm that supervised fine-tuning with LoRA is ineffective for learning from retry data and that full-parameter pre-training is a necessary requirement for that task. We showcase that the self-correcting behavior is learned by the model and the increase in downstream accuracy metrics is a result of this additional skill. Finally, we incorporate RetrySQL-trained models into the full text-to-SQL pipeline and showcase that they are competitive in terms of execution accuracy with proprietary models that contain orders of magnitude more parameters. RetrySQL demonstrates that self-correction can be learned in the text-to-SQL task and provides a novel way of improving generation accuracy for SQL-oriented language models.
Classical Out-of-Distribution Detection Methods Benchmark in Text Classification Tasks
Jul 13, 2023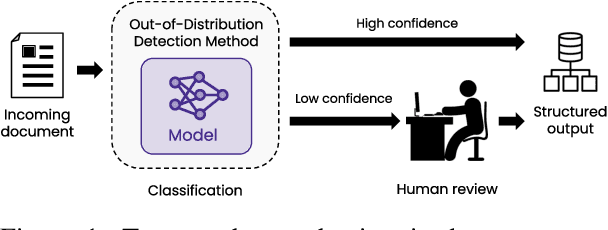
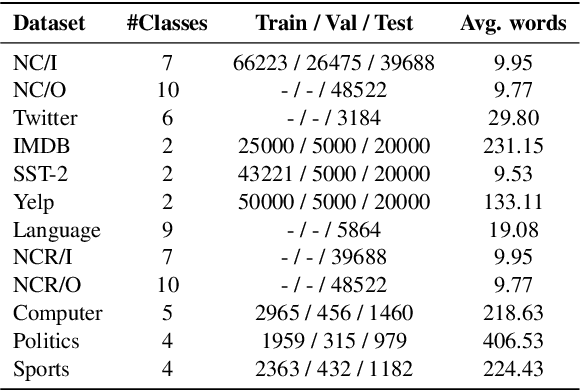
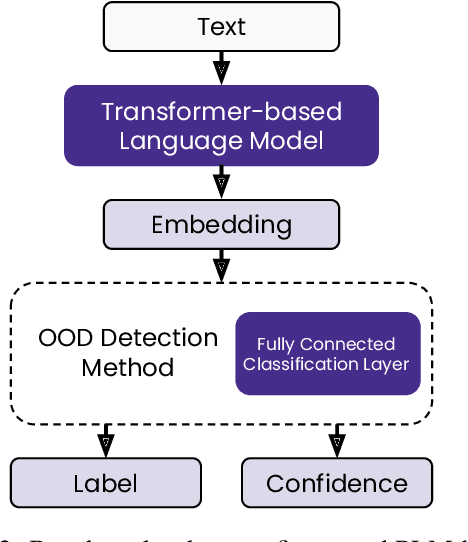
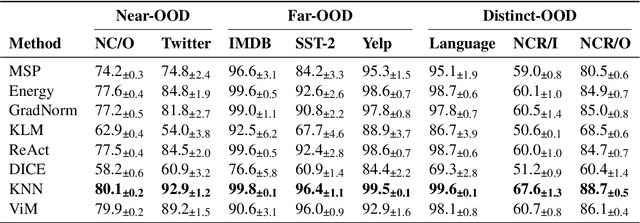
State-of-the-art models can perform well in controlled environments, but they often struggle when presented with out-of-distribution (OOD) examples, making OOD detection a critical component of NLP systems. In this paper, we focus on highlighting the limitations of existing approaches to OOD detection in NLP. Specifically, we evaluated eight OOD detection methods that are easily integrable into existing NLP systems and require no additional OOD data or model modifications. One of our contributions is providing a well-structured research environment that allows for full reproducibility of the results. Additionally, our analysis shows that existing OOD detection methods for NLP tasks are not yet sufficiently sensitive to capture all samples characterized by various types of distributional shifts. Particularly challenging testing scenarios arise in cases of background shift and randomly shuffled word order within in domain texts. This highlights the need for future work to develop more effective OOD detection approaches for the NLP problems, and our work provides a well-defined foundation for further research in this area.
ChatGPT: Jack of all trades, master of none
Feb 21, 2023



OpenAI has released the Chat Generative Pre-trained Transformer (ChatGPT) and revolutionized the approach in artificial intelligence to human-model interaction. The first contact with the chatbot reveals its ability to provide detailed and precise answers in various areas. There are several publications on ChatGPT evaluation, testing its effectiveness on well-known natural language processing (NLP) tasks. However, the existing studies are mostly non-automated and tested on a very limited scale. In this work, we examined ChatGPT's capabilities on 25 diverse analytical NLP tasks, most of them subjective even to humans, such as sentiment analysis, emotion recognition, offensiveness and stance detection, natural language inference, word sense disambiguation, linguistic acceptability and question answering. We automated ChatGPT's querying process and analyzed more than 38k responses. Our comparison of its results with available State-of-the-Art (SOTA) solutions showed that the average loss in quality of the ChatGPT model was about 25% for zero-shot and few-shot evaluation. We showed that the more difficult the task (lower SOTA performance), the higher the ChatGPT loss. It especially refers to pragmatic NLP problems like emotion recognition. We also tested the ability of personalizing ChatGPT responses for selected subjective tasks via Random Contextual Few-Shot Personalization, and we obtained significantly better user-based predictions. Additional qualitative analysis revealed a ChatGPT bias, most likely due to the rules imposed on human trainers by OpenAI. Our results provide the basis for a fundamental discussion of whether the high quality of recent predictive NLP models can indicate a tool's usefulness to society and how the learning and validation procedures for such systems should be established.