 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLLuM: A Family of Polish Large Language Models
Nov 05, 2025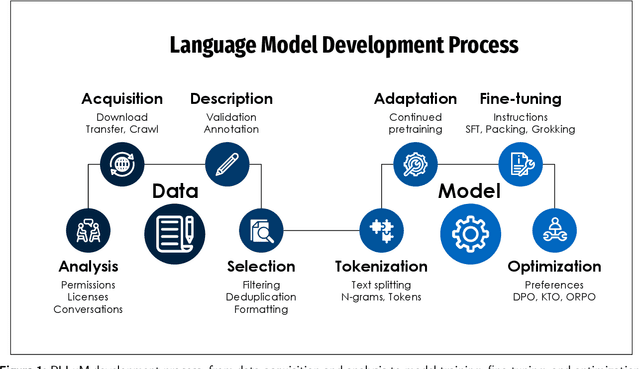
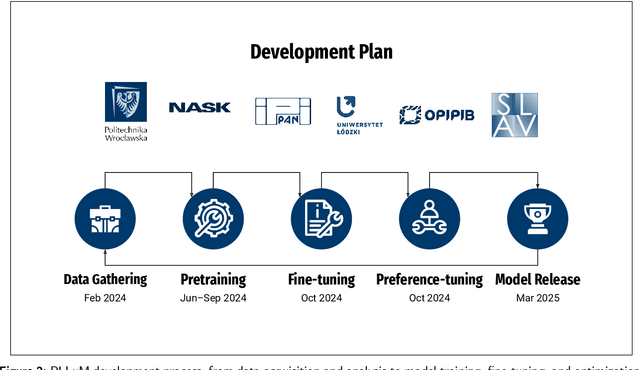

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
Investigating large language models for their competence in extracting grammatically sound sentences from transcribed noisy utterances
Oct 07, 2024Selectively processing noisy utterances while effectively disregarding speech-specific elements poses no considerable challenge for humans, as they exhibit remarkable cognitive abilities to separate semantically significant content from speech-specific noise (i.e. filled pauses, disfluencies, and restarts). These abilities may be driven by mechanisms based on acquired grammatical rules that compose abstract syntactic-semantic structures within utterances. Segments without syntactic and semantic significance are consistently disregarded in these structures. The structures, in tandem with lexis, likely underpin language comprehension and thus facilitate effective communication. In our study, grounded in linguistically motivated experiments, we investigate whether large language models (LLMs) can effectively perform analogical speech comprehension tasks. In particular, we examine the ability of LLMs to extract well-structured utterances from transcriptions of noisy dialogues. We conduct two evaluation experiments in the Polish language scenario, using a~dataset presumably unfamiliar to LLMs to mitigate the risk of data contamination. Our results show that not all extracted utterances are correctly structured, indicating that either LLMs do not fully acquire syntactic-semantic rules or they acquire them but cannot apply them effectively. We conclude that the ability of LLMs to comprehend noisy utterances is still relatively superficial compared to human proficiency in processing them.
NLPre: a revised approach towards language-centric benchmarking of Natural Language Preprocessing systems
Mar 07, 2024



With the advancements of transformer-based architectures, we observe the rise of natural language preprocessing (NLPre) tools capable of solving preliminary NLP tasks (e.g. tokenisation, part-of-speech tagging, dependency parsing, or morphological analysis) without any external linguistic guidance. It is arduous to compare novel solutions to well-entrenched preprocessing toolkits, relying on rule-based morphological analysers or dictionaries. Aware of the shortcomings of existing NLPre evaluation approaches, we investigate a novel method of reliable and fair evaluation and performance reporting. Inspired by the GLUE benchmark, the proposed language-centric benchmarking system enables comprehensive ongoing evaluation of multiple NLPre tools, while credibly tracking their performance. The prototype application is configured for Polish and integrated with the thoroughly assembled NLPre-PL benchmark. Based on this benchmark, we conduct an extensive evaluation of a variety of Polish NLPre systems. To facilitate the construction of benchmarking environments for other languages, e.g. NLPre-GA for Irish or NLPre-ZH for Chinese, we ensure full customization of the publicly released source code of the benchmarking system. The links to all the resources (deployed platforms, source code, trained models, datasets etc.) can be found on the project website: https://sites.google.com/view/nlpre-benchmark.
COMBO: State-of-the-Art Morphosyntactic Analysis
Sep 11, 2021
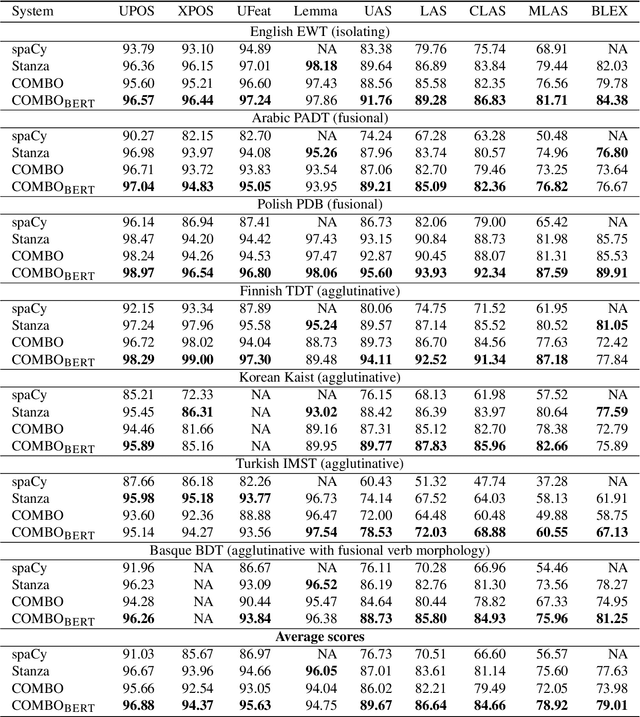
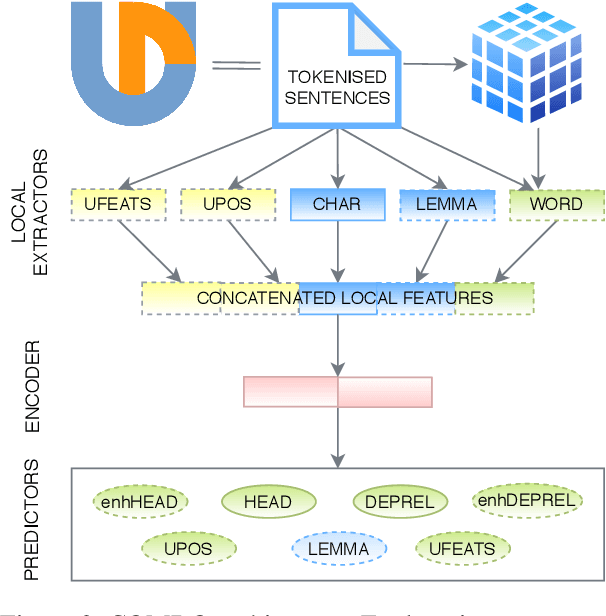

We introduce COMBO - a fully neural NLP system for accurate part-of-speech tagging, morphological analysis, lemmatisation, and (enhanced) dependency parsing. It predicts categorical morphosyntactic features whilst also exposes their vector representations, extracted from hidden layers. COMBO is an easy to install Python package with automatically downloadable pre-trained models for over 40 languages. It maintains a balance between efficiency and quality. As it is an end-to-end system and its modules are jointly trained, its training is competitively fast. As its models are optimised for accuracy, they achieve often better prediction quality than SOTA. The COMBO library is available at: https://gitlab.clarin-pl.eu/syntactic-tools/combo.
COMBO: a new module for EUD parsing
Jul 08, 2021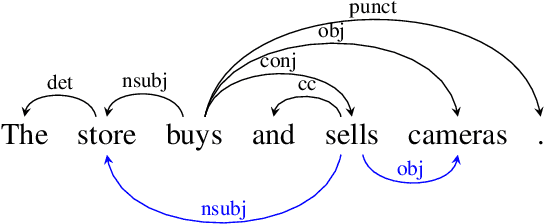

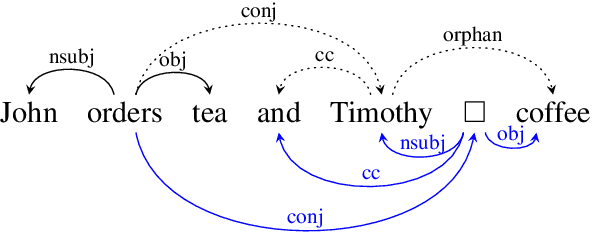
We introduce the COMBO-based approach for EUD parsing and its implementation, which took part in the IWPT 2021 EUD shared task. The goal of this task is to parse raw texts in 17 languages into Enhanced Universal Dependencies (EUD). The proposed approach uses COMBO to predict UD trees and EUD graphs. These structures are then merged into the final EUD graphs. Some EUD edge labels are extended with case information using a single language-independent expansion rule. In the official evaluation, the solution ranked fourth, achieving an average ELAS of 83.79%. The source code is available at https://gitlab.clarin-pl.eu/syntactic-tools/combo.
HerBERT: Efficiently Pretrained Transformer-based Language Model for Polish
May 04, 2021
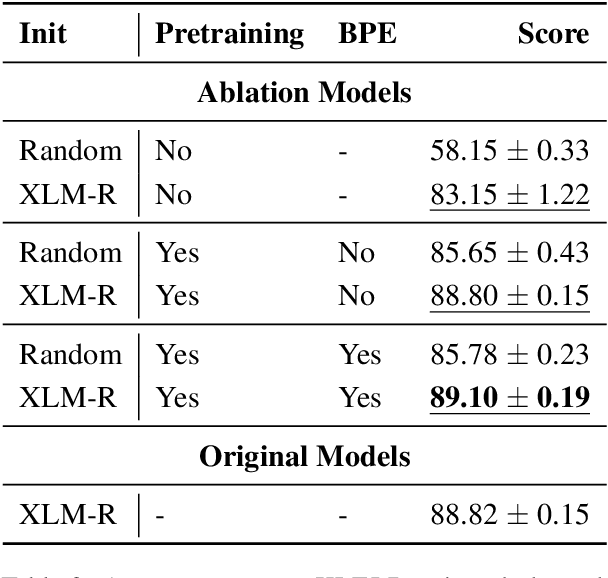


BERT-based models are currently used for solving nearly all Natural Language Processing (NLP) tasks and most often achieve state-of-the-art results. Therefore, the NLP community conducts extensive research on understanding these models, but above all on designing effective and efficient training procedures. Several ablation studies investigating how to train BERT-like models have been carried out, but the vast majority of them concerned only the English language. A training procedure designed for English does not have to be universal and applicable to other especially typologically different languages. Therefore, this paper presents the first ablation study focused on Polish, which, unlike the isolating English language, is a fusional language. We design and thoroughly evaluate a pretraining procedure of transferring knowledge from multilingual to monolingual BERT-based models. In addition to multilingual model initialization, other factors that possibly influence pretraining are also explored, i.e. training objective, corpus size, BPE-Dropout, and pretraining length. Based on the proposed procedure, a Polish BERT-based language model -- HerBERT -- is trained. This model achieves state-of-the-art results on multiple downstream tasks.
Semi-Supervised Neural System for Tagging, Parsing and Lematization
Apr 26, 2020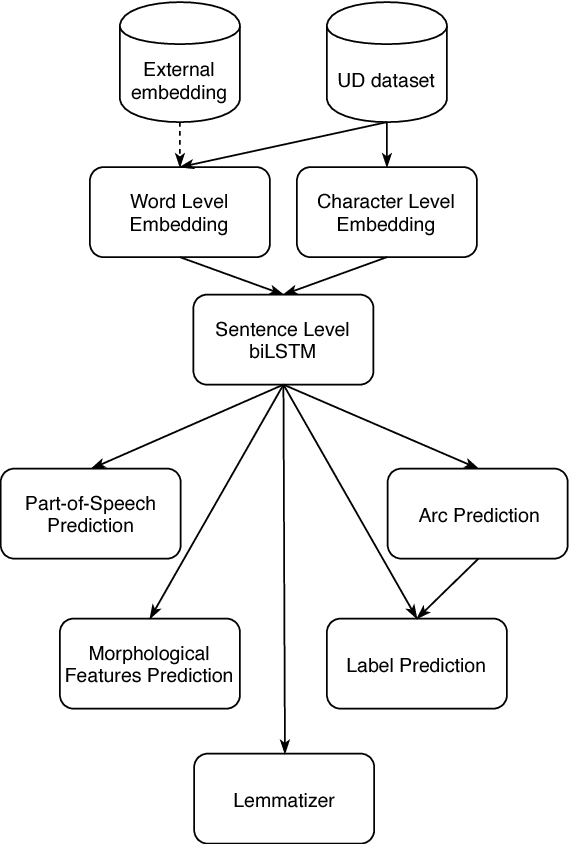

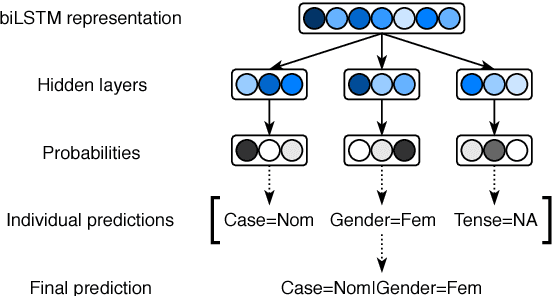

This paper describes the ICS PAS system which took part in CoNLL 2018 shared task on Multilingual Parsing from Raw Text to Universal Dependencies. The system consists of jointly trained tagger, lemmatizer, and dependency parser which are based on features extracted by a biLSTM network. The system uses both fully connected and dilated convolutional neural architectures. The novelty of our approach is the use of an additional loss function, which reduces the number of cycles in the predicted dependency graphs, and the use of self-training to increase the system performance. The proposed system, i.e. ICS PAS (Warszawa), ranked 3th/4th in the official evaluation obtaining the following overall results: 73.02 (LAS), 60.25 (MLAS) and 64.44 (BLEX).