 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Few-Shot Learning for Classification Tasks in the Polish Language
Apr 27, 2024
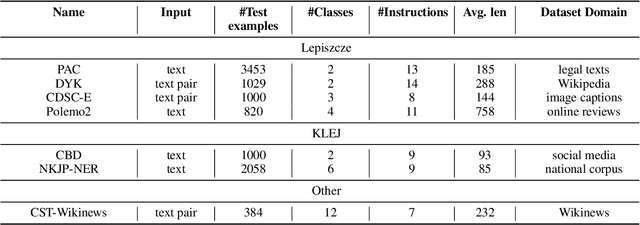


We introduce a few-shot benchmark consisting of 7 different classification tasks native to the Polish language. We conducted an empirical comparison with 0 and 16 shots between fine-tuning, linear probing, SetFit, and in-context learning (ICL) using various pre-trained commercial and open-source models. Our findings reveal that ICL achieves the best performance, with commercial models like GPT-3.5 and GPT-4 attaining the best performance. However, there remains a significant 14 percentage points gap between our best few-shot learning score and the performance of HerBERT-large fine-tuned on the entire training dataset. Among the techniques, SetFit emerges as the second-best approach, closely followed by linear probing. We observed the worst and most unstable performance with non-linear head fine-tuning. Results for ICL indicate that continual pre-training of models like Mistral-7b or Llama-2-13b on Polish corpora is beneficial. This is confirmed by the improved performances of Bielik-7b and Trurl-13b, respectively. To further support experiments in few-shot learning for Polish, we are releasing handcrafted templates for the ICL.
Going beyond research datasets: Novel intent discovery in the industry setting
May 09, 2023Novel intent discovery automates the process of grouping similar messages (questions) to identify previously unknown intents. However, current research focuses on publicly available datasets which have only the question field and significantly differ from real-life datasets. This paper proposes methods to improve the intent discovery pipeline deployed in a large e-commerce platform. We show the benefit of pre-training language models on in-domain data: both self-supervised and with weak supervision. We also devise the best method to utilize the conversational structure (i.e., question and answer) of real-life datasets during fine-tuning for clustering tasks, which we call Conv. All our methods combined to fully utilize real-life datasets give up to 33pp performance boost over state-of-the-art Constrained Deep Adaptive Clustering (CDAC) model for question only. By comparison CDAC model for the question data only gives only up to 13pp performance boost over the naive baseline.
Evaluation of Transfer Learning for Polish with a Text-to-Text Model
May 18, 2022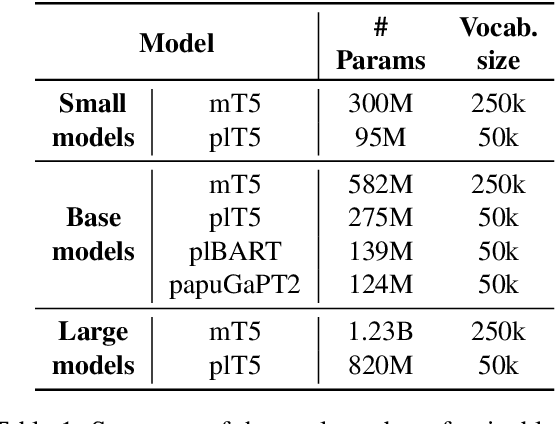

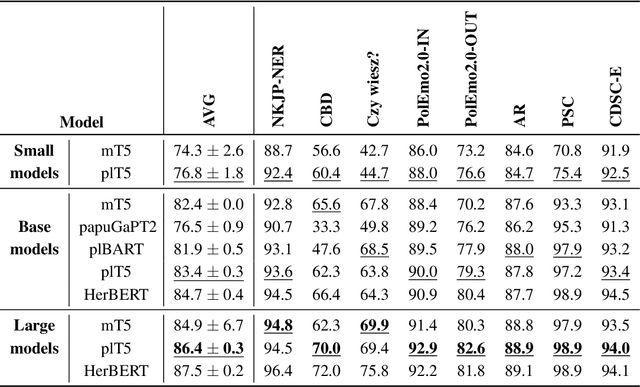
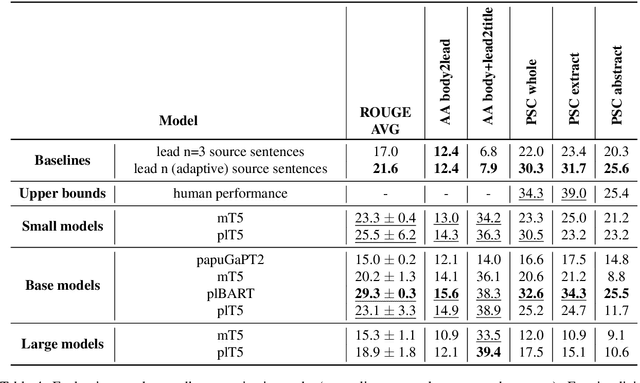
We introduce a new benchmark for assessing the quality of text-to-text models for Polish. The benchmark consists of diverse tasks and datasets: KLEJ benchmark adapted for text-to-text, en-pl translation, summarization, and question answering. In particular, since summarization and question answering lack benchmark datasets for the Polish language, we describe their construction and make them publicly available. Additionally, we present plT5 - a general-purpose text-to-text model for Polish that can be fine-tuned on various Natural Language Processing (NLP) tasks with a single training objective. Unsupervised denoising pre-training is performed efficiently by initializing the model weights with a multi-lingual T5 (mT5) counterpart. We evaluate the performance of plT5, mT5, Polish BART (plBART), and Polish GPT-2 (papuGaPT2). The plT5 scores top on all of these tasks except summarization, where plBART is best. In general (except for summarization), the larger the model, the better the results. The encoder-decoder architectures prove to be better than the decoder-only equivalent.