 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Few-Shot Learning for Classification Tasks in the Polish Language
Paper and Code

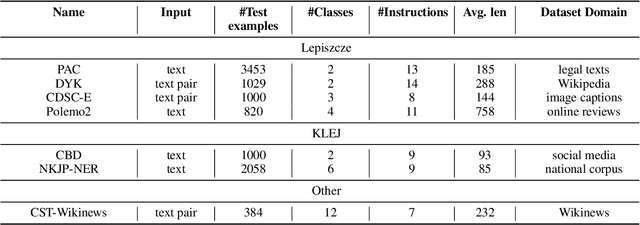


We introduce a few-shot benchmark consisting of 7 different classification tasks native to the Polish language. We conducted an empirical comparison with 0 and 16 shots between fine-tuning, linear probing, SetFit, and in-context learning (ICL) using various pre-trained commercial and open-source models. Our findings reveal that ICL achieves the best performance, with commercial models like GPT-3.5 and GPT-4 attaining the best performance. However, there remains a significant 14 percentage points gap between our best few-shot learning score and the performance of HerBERT-large fine-tuned on the entire training dataset. Among the techniques, SetFit emerges as the second-best approach, closely followed by linear probing. We observed the worst and most unstable performance with non-linear head fine-tuning. Results for ICL indicate that continual pre-training of models like Mistral-7b or Llama-2-13b on Polish corpora is beneficial. This is confirmed by the improved performances of Bielik-7b and Trurl-13b, respectively. To further support experiments in few-shot learning for Polish, we are releasing handcrafted templates for the ICL.