Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Criminal Texts for the Polish State Border Guard
Paper and Code
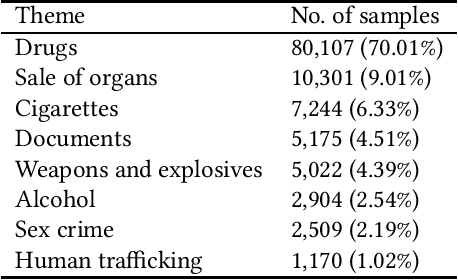
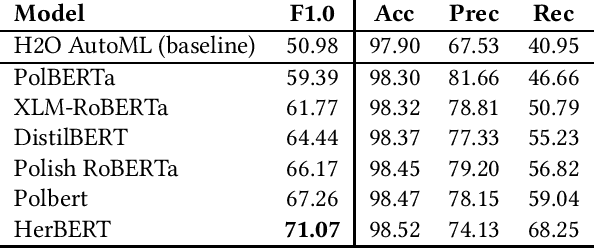
This paper describes research on the detection of Polish criminal texts appearing on the Internet. We carried out experiments to find the best available setup for the efficient classification of unbalanced and noisy data. The best performance was achieved when our model was fine-tuned on a pre-trained Polish-based transformer language model. For the detection task, a large corpus of annotated Internet snippets was collected as training data. We share this dataset and create a new task for the detection of criminal texts using the Gonito platform as the benchmark.
* Accepted for MIS2 workshop at KDD 2021
View paper on