 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Approximate Single-Source Shortest Paths with Predictions
Feb 12, 2025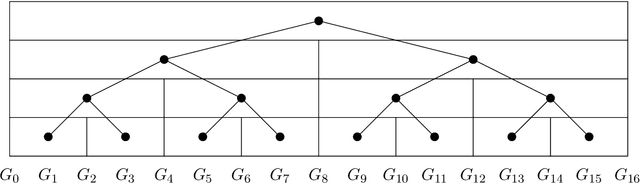
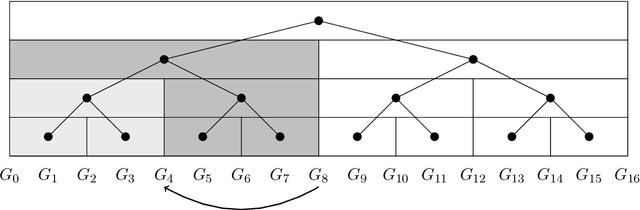
The algorithms-with-predictions framework has been used extensively to develop online algorithms with improved beyond-worst-case competitive ratios. Recently, there is growing interest in leveraging predictions for designing data structures with improved beyond-worst-case running times. In this paper, we study the fundamental data structure problem of maintaining approximate shortest paths in incremental graphs in the algorithms-with-predictions model. Given a sequence $\sigma$ of edges that are inserted one at a time, the goal is to maintain approximate shortest paths from the source to each vertex in the graph at each time step. Before any edges arrive, the data structure is given a prediction of the online edge sequence $\hat{\sigma}$ which is used to ``warm start'' its state. As our main result, we design a learned algorithm that maintains $(1+\epsilon)$-approximate single-source shortest paths, which runs in $\tilde{O}(m \eta \log W/\epsilon)$ time, where $W$ is the weight of the heaviest edge and $\eta$ is the prediction error. We show these techniques immediately extend to the all-pairs shortest-path setting as well. Our algorithms are consistent (performing nearly as fast as the offline algorithm) when predictions are nearly perfect, have a smooth degradation in performance with respect to the prediction error and, in the worst case, match the best offline algorithm up to logarithmic factors. As a building block, we study the offline incremental approximate single-source shortest-paths problem. In this problem, the edge sequence $\sigma$ is known a priori and the goal is to efficiently return the length of the shortest paths in the intermediate graph $G_t$ consisting of the first $t$ edges, for all $t$. Note that the offline incremental problem is defined in the worst-case setting (without predictions) and is of independent interest.
Online List Labeling with Predictions
May 17, 2023



A growing line of work shows how learned predictions can be used to break through worst-case barriers to improve the running time of an algorithm. However, incorporating predictions into data structures with strong theoretical guarantees remains underdeveloped. This paper takes a step in this direction by showing that predictions can be leveraged in the fundamental online list labeling problem. In the problem, n items arrive over time and must be stored in sorted order in an array of size Theta(n). The array slot of an element is its label and the goal is to maintain sorted order while minimizing the total number of elements moved (i.e., relabeled). We design a new list labeling data structure and bound its performance in two models. In the worst-case learning-augmented model, we give guarantees in terms of the error in the predictions. Our data structure provides strong guarantees: it is optimal for any prediction error and guarantees the best-known worst-case bound even when the predictions are entirely erroneous. We also consider a stochastic error model and bound the performance in terms of the expectation and variance of the error. Finally, the theoretical results are demonstrated empirically. In particular, we show that our data structure has strong performance on real temporal data sets where predictions are constructed from elements that arrived in the past, as is typically done in a practical use case.
Agent-update Models
Nov 04, 2022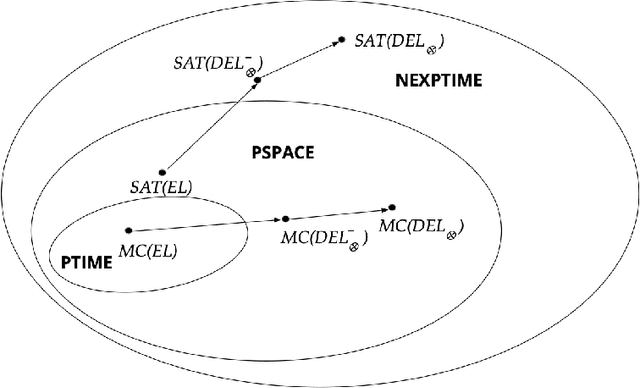
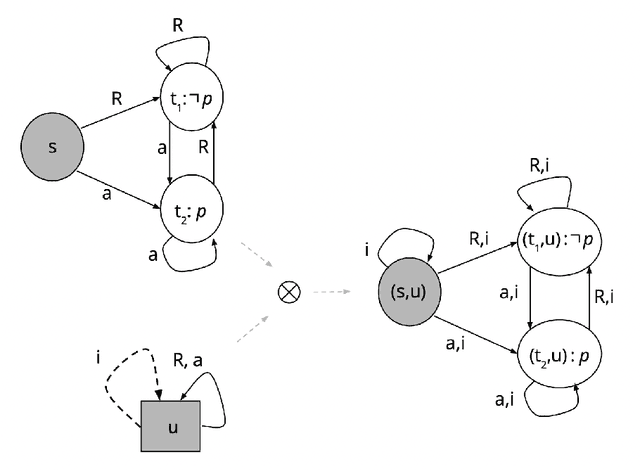
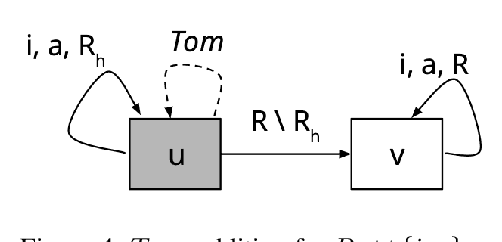
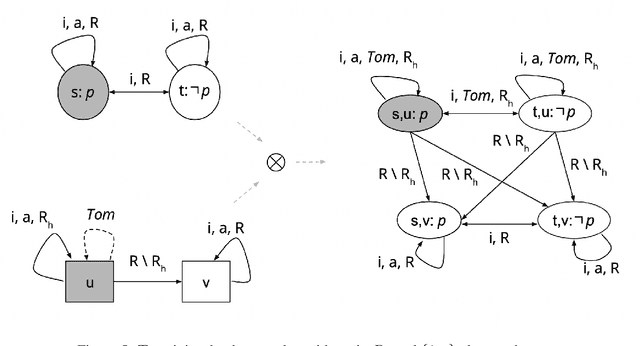
In dynamic epistemic logic (Van Ditmarsch et al., 2008) it is customary to use an action model (Baltag and Moss, 2004; Baltag et al., 1998) to describe different views of a single action. In this article, action models are extended to add or remove agents, we call these agent-update models. This can be done selectively so that only some specified agents get information of the update, which can be used to model several interesting examples such as private update and deception, studied earlier by Baltag and Moss (2004); Sakama (2015); Van Ditmarsch et al. (2012). The product update of a Kripke model by an action model is an abbreviated way of describing the transformed Kripke model which is the result of performing the action. This is extended to a sum-product update of a Kripke model by an agent-update model in the new setting. We show that dynamic doxastic logic with action modalities, now based on agent-update models, continues to have a sound and complete proof system. We have simple decision procedures for model checking and validity.
Subjective Knowledge and Reasoning about Agents in Multi-Agent Systems
Jan 22, 2020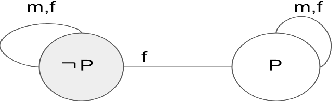
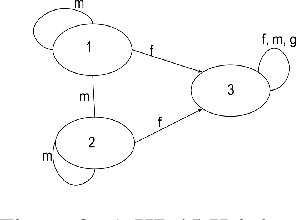
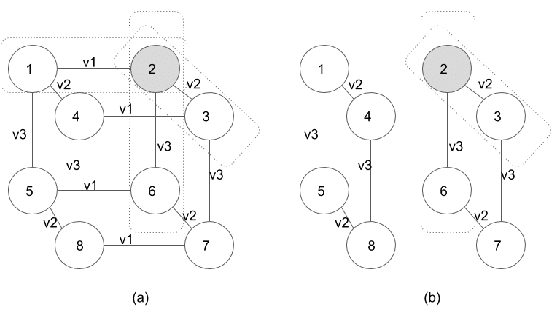
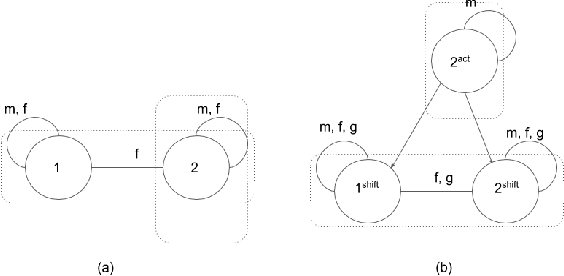
Though a lot of work in multi-agent systems is focused on reasoning about knowledge and beliefs of artificial agents, an explicit representation and reasoning about the presence/absence of agents, especially in the scenarios where agents may be unaware of other agents joining in or going offline in a multi-agent system, leading to partial knowledge/asymmetric knowledge of the agents is mostly overlooked by the MAS community. Such scenarios lay the foundations of cases where an agent can influence other agents' mental states by (mis)informing them about the presence/absence of collaborators or adversaries. In this paper, we investigate how Kripke structure-based epistemic models can be extended to express the above notion based on an agent's subjective knowledge and we discuss the challenges that come along.
Deep Sparse Coding for Non-Intrusive Load Monitoring
Dec 11, 2019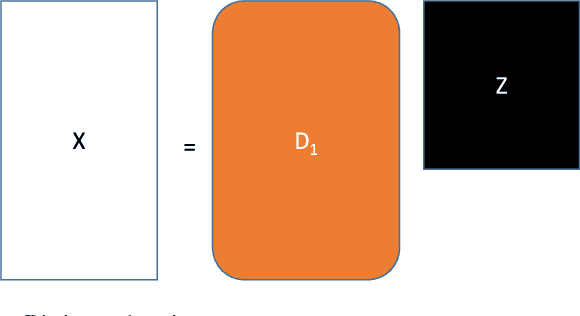
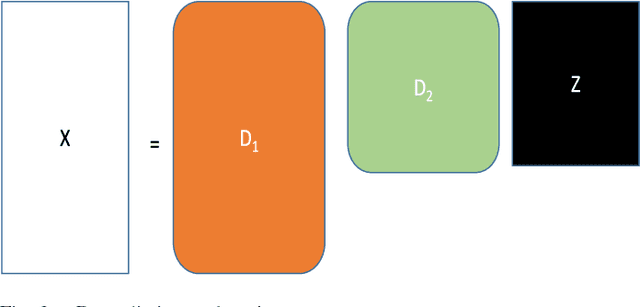
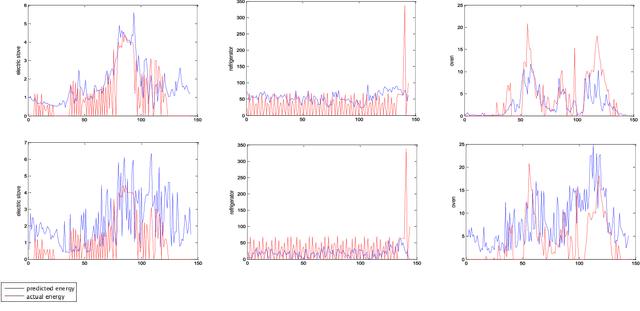

Energy disaggregation is the task of segregating the aggregate energy of the entire building (as logged by the smartmeter) into the energy consumed by individual appliances. This is a single channel (the only channel being the smart-meter) blind source (different electrical appliances) separation problem. The traditional way to address this is via stochastic finite state machines (e.g. Factorial Hidden Markov Model). In recent times dictionary learning based approaches have shown promise in addressing the disaggregation problem. The usual technique is to learn a dictionary for every device and use the learnt dictionaries as basis for blind source separation during disaggregation. Prior studies in this area are shallow learning techniques, i.e. they learn a single layer of dictionary for every device. In this work, we propose a deep learning approach, instead of learning one level of dictionary, we learn multiple layers of dictionaries for each device. These multi-level dictionaries are used as a basis for source separation during disaggregation. Results on two benchmark datasets and one actual implementation show that our method outperforms state-of-the-art techniques.
Analysis Co-Sparse Coding for Energy Disaggregation
Dec 11, 2019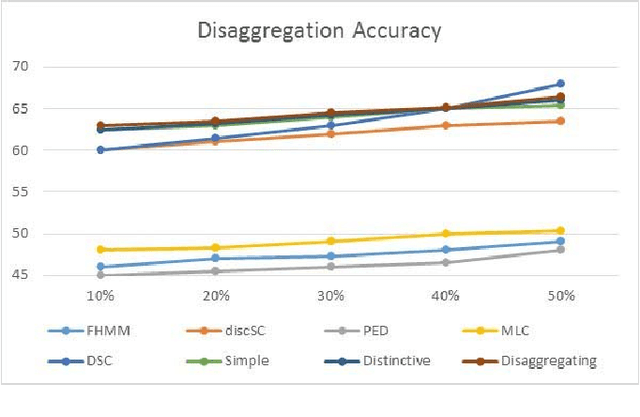

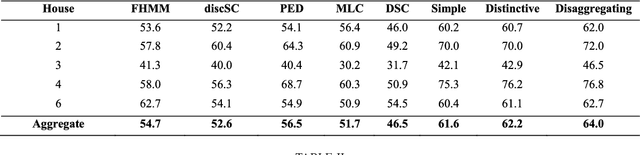
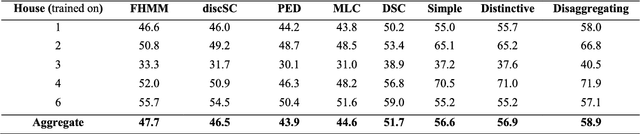
Energy disaggregation is the task of segregating the aggregate energy of the entire building (as logged by the smartmeter) into the energy consumed by individual appliances. This is a single channel (the only channel being the smart-meter) blind source (different electrical appliances) separation problem. In recent times dictionary learning based approaches have shown promise in addressing the disaggregation problem. The usual technique is to learn a dictionary for every device and use the learnt dictionaries as basis for blind source separation during disaggregation. Dictionary learning is a synthesis formulation; in this work, we propose an analysis approach. The advantage of our proposed approach is that, the requirement of training volume drastically reduces compared to state-of-the-art techniques. This means that, we require fewer instrumented homes, or fewer days of instrumentation per home; in either case this drastically reduces the sensing cost. Results on two benchmark datasets show that our method produces the same level of disaggregation accuracy as state-of-the-art methods but with only a fraction of the training data.
Non-intrusive Load Monitoring via Multi-label Sparse Representation based Classification
Dec 11, 2019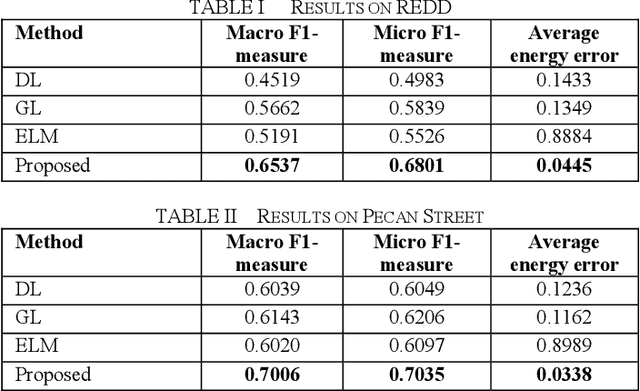
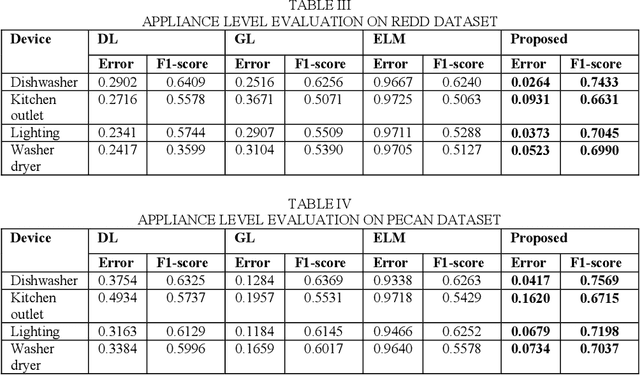
This work follows the approach of multi-label classification for non-intrusive load monitoring (NILM). We modify the popular sparse representation based classification (SRC) approach (developed for single label classification) to solve multi-label classification problems. Results on benchmark REDD and Pecan Street dataset shows significant improvement over state-of-the-art techniques with small volume of training data.
Multi Label Restricted Boltzmann Machine for Non-Intrusive Load Monitoring
Oct 17, 2019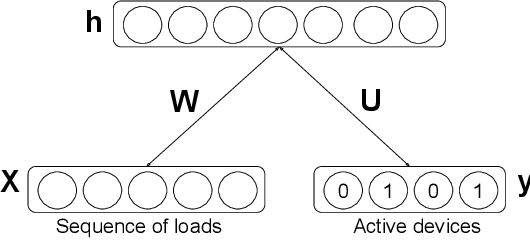
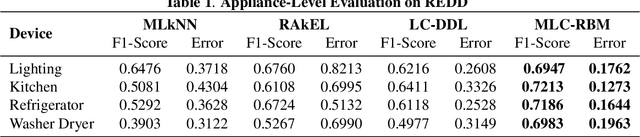
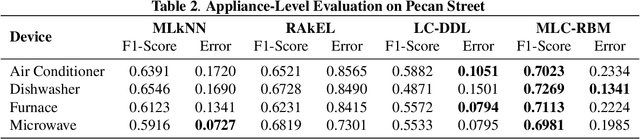
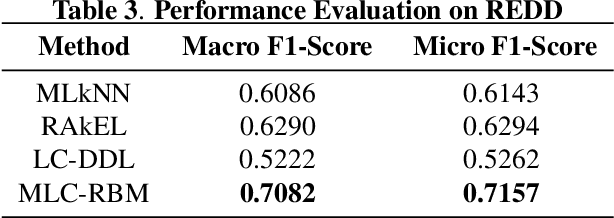
Increasing population indicates that energy demands need to be managed in the residential sector. Prior studies have reflected that the customers tend to reduce a significant amount of energy consumption if they are provided with appliance-level feedback. This observation has increased the relevance of load monitoring in today's tech-savvy world. Most of the previously proposed solutions claim to perform load monitoring without intrusion, but they are not completely non-intrusive. These methods require historical appliance-level data for training the model for each of the devices. This data is gathered by putting a sensor on each of the appliances present in the home which causes intrusion in the building. Some recent studies have proposed that if we frame Non-Intrusive Load Monitoring (NILM) as a multi-label classification problem, the need for appliance-level data can be avoided. In this paper, we propose Multi-label Restricted Boltzmann Machine(ML-RBM) for NILM and report an experimental evaluation of proposed and state-of-the-art techniques.
How to Train Your Deep Neural Network with Dictionary Learning
Dec 22, 2016
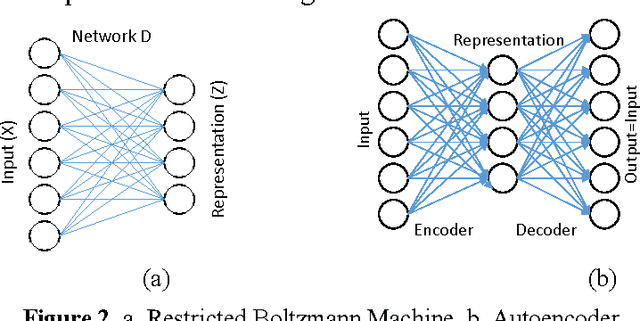
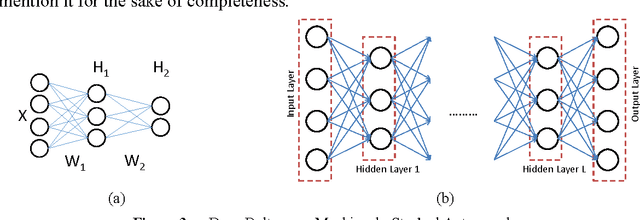
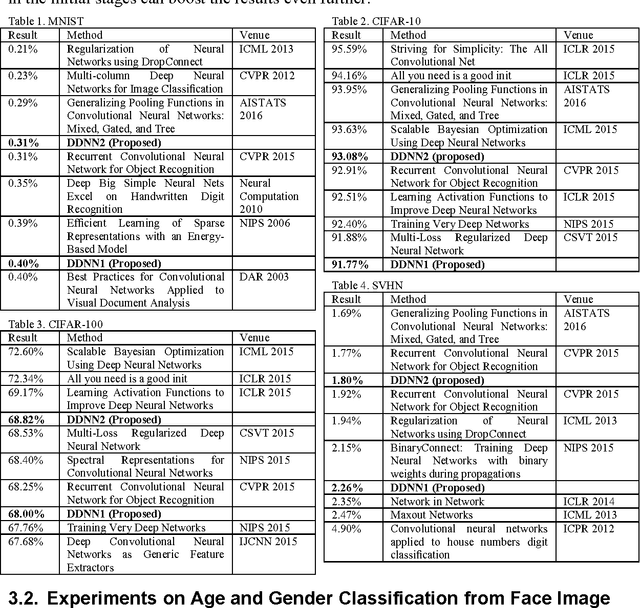
Currently there are two predominant ways to train deep neural networks. The first one uses restricted Boltzmann machine (RBM) and the second one autoencoders. RBMs are stacked in layers to form deep belief network (DBN); the final representation layer is attached to the target to complete the deep neural network. Autoencoders are nested one inside the other to form stacked autoencoders; once the stcaked autoencoder is learnt the decoder portion is detached and the target attached to the deepest layer of the encoder to form the deep neural network. This work proposes a new approach to train deep neural networks using dictionary learning as the basic building block; the idea is to use the features from the shallower layer as inputs for training the next deeper layer. One can use any type of dictionary learning (unsupervised, supervised, discriminative etc.) as basic units till the pre-final layer. In the final layer one needs to use the label consistent dictionary learning formulation for classification. We compare our proposed framework with existing state-of-the-art deep learning techniques on benchmark problems; we are always within the top 10 results. In actual problems of age and gender classification, we are better than the best known techniques.
Deep Blind Compressed Sensing
Dec 22, 2016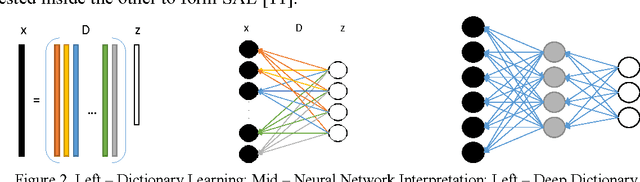
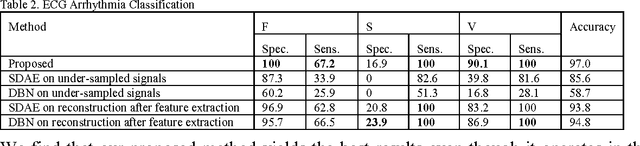
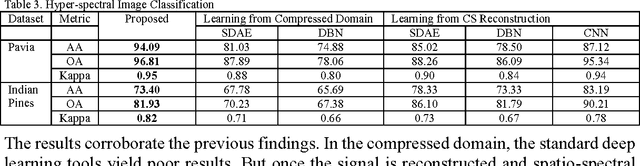
This work addresses the problem of extracting deeply learned features directly from compressive measurements. There has been no work in this area. Existing deep learning tools only give good results when applied on the full signal, that too usually after preprocessing. These techniques require the signal to be reconstructed first. In this work we show that by learning directly from the compressed domain, considerably better results can be obtained. This work extends the recently proposed framework of deep matrix factorization in combination with blind compressed sensing; hence the term deep blind compressed sensing. Simulation experiments have been carried out on imaging via single pixel camera, under-sampled biomedical signals, arising in wireless body area network and compressive hyperspectral imaging. In all cases, the superiority of our proposed deep blind compressed sensing can be envisaged.