 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Approximate Single-Source Shortest Paths with Predictions
Feb 12, 2025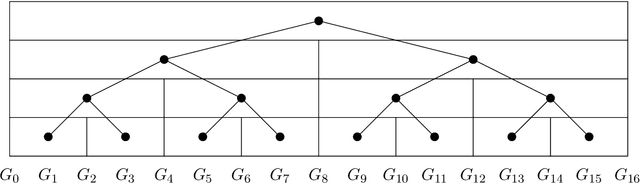
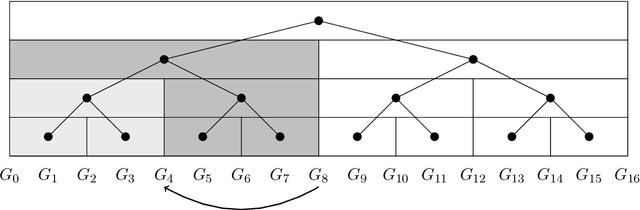
The algorithms-with-predictions framework has been used extensively to develop online algorithms with improved beyond-worst-case competitive ratios. Recently, there is growing interest in leveraging predictions for designing data structures with improved beyond-worst-case running times. In this paper, we study the fundamental data structure problem of maintaining approximate shortest paths in incremental graphs in the algorithms-with-predictions model. Given a sequence $\sigma$ of edges that are inserted one at a time, the goal is to maintain approximate shortest paths from the source to each vertex in the graph at each time step. Before any edges arrive, the data structure is given a prediction of the online edge sequence $\hat{\sigma}$ which is used to ``warm start'' its state. As our main result, we design a learned algorithm that maintains $(1+\epsilon)$-approximate single-source shortest paths, which runs in $\tilde{O}(m \eta \log W/\epsilon)$ time, where $W$ is the weight of the heaviest edge and $\eta$ is the prediction error. We show these techniques immediately extend to the all-pairs shortest-path setting as well. Our algorithms are consistent (performing nearly as fast as the offline algorithm) when predictions are nearly perfect, have a smooth degradation in performance with respect to the prediction error and, in the worst case, match the best offline algorithm up to logarithmic factors. As a building block, we study the offline incremental approximate single-source shortest-paths problem. In this problem, the edge sequence $\sigma$ is known a priori and the goal is to efficiently return the length of the shortest paths in the intermediate graph $G_t$ consisting of the first $t$ edges, for all $t$. Note that the offline incremental problem is defined in the worst-case setting (without predictions) and is of independent interest.
Binary Search with Distributional Predictions
Nov 25, 2024Algorithms with (machine-learned) predictions is a powerful framework for combining traditional worst-case algorithms with modern machine learning. However, the vast majority of work in this space assumes that the prediction itself is non-probabilistic, even if it is generated by some stochastic process (such as a machine learning system). This is a poor fit for modern ML, particularly modern neural networks, which naturally generate a distribution. We initiate the study of algorithms with distributional predictions, where the prediction itself is a distribution. We focus on one of the simplest yet fundamental settings: binary search (or searching a sorted array). This setting has one of the simplest algorithms with a point prediction, but what happens if the prediction is a distribution? We show that this is a richer setting: there are simple distributions where using the classical prediction-based algorithm with any single prediction does poorly. Motivated by this, as our main result, we give an algorithm with query complexity $O(H(p) + \log \eta)$, where $H(p)$ is the entropy of the true distribution $p$ and $\eta$ is the earth mover's distance between $p$ and the predicted distribution $\hat p$. This also yields the first distributionally-robust algorithm for the classical problem of computing an optimal binary search tree given a distribution over target keys. We complement this with a lower bound showing that this query complexity is essentially optimal (up to constants), and experiments validating the practical usefulness of our algorithm.
Online List Labeling with Predictions
May 17, 2023



A growing line of work shows how learned predictions can be used to break through worst-case barriers to improve the running time of an algorithm. However, incorporating predictions into data structures with strong theoretical guarantees remains underdeveloped. This paper takes a step in this direction by showing that predictions can be leveraged in the fundamental online list labeling problem. In the problem, n items arrive over time and must be stored in sorted order in an array of size Theta(n). The array slot of an element is its label and the goal is to maintain sorted order while minimizing the total number of elements moved (i.e., relabeled). We design a new list labeling data structure and bound its performance in two models. In the worst-case learning-augmented model, we give guarantees in terms of the error in the predictions. Our data structure provides strong guarantees: it is optimal for any prediction error and guarantees the best-known worst-case bound even when the predictions are entirely erroneous. We also consider a stochastic error model and bound the performance in terms of the expectation and variance of the error. Finally, the theoretical results are demonstrated empirically. In particular, we show that our data structure has strong performance on real temporal data sets where predictions are constructed from elements that arrived in the past, as is typically done in a practical use case.