 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-update Models
Nov 04, 2022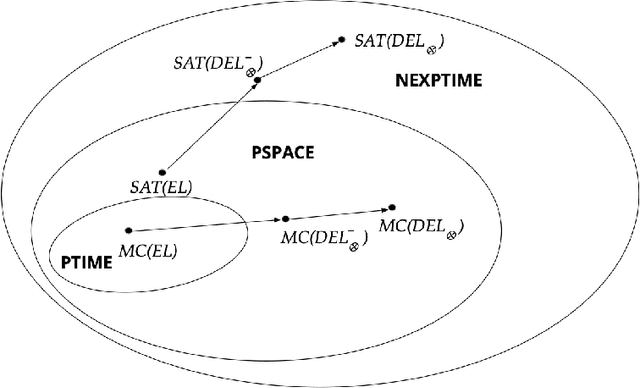
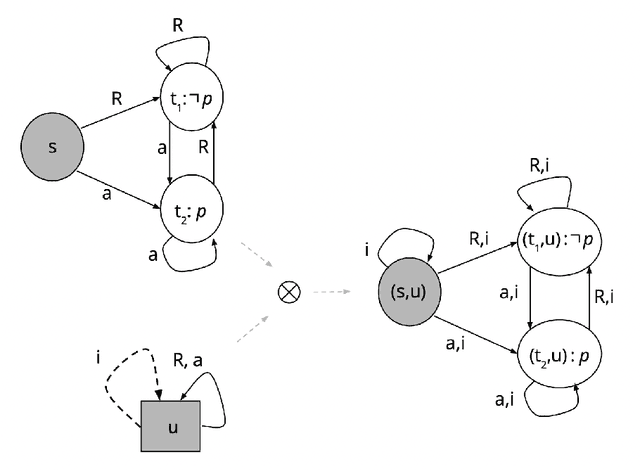
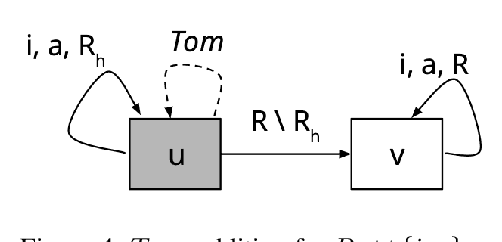
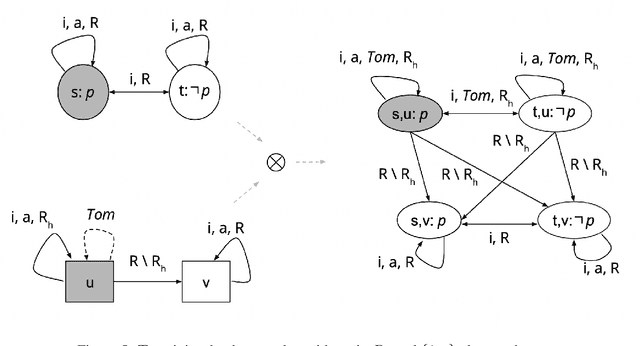
In dynamic epistemic logic (Van Ditmarsch et al., 2008) it is customary to use an action model (Baltag and Moss, 2004; Baltag et al., 1998) to describe different views of a single action. In this article, action models are extended to add or remove agents, we call these agent-update models. This can be done selectively so that only some specified agents get information of the update, which can be used to model several interesting examples such as private update and deception, studied earlier by Baltag and Moss (2004); Sakama (2015); Van Ditmarsch et al. (2012). The product update of a Kripke model by an action model is an abbreviated way of describing the transformed Kripke model which is the result of performing the action. This is extended to a sum-product update of a Kripke model by an agent-update model in the new setting. We show that dynamic doxastic logic with action modalities, now based on agent-update models, continues to have a sound and complete proof system. We have simple decision procedures for model checking and validity.
Subjective Knowledge and Reasoning about Agents in Multi-Agent Systems
Jan 22, 2020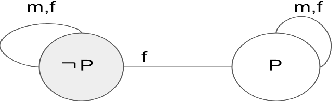
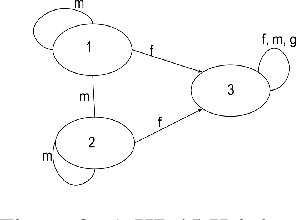
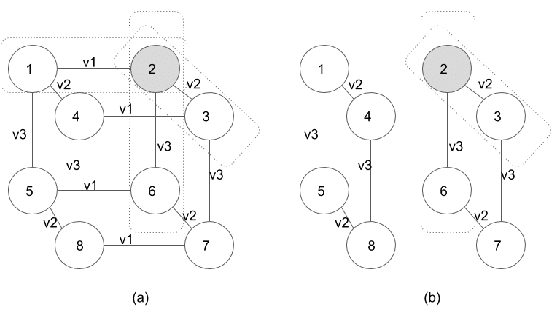
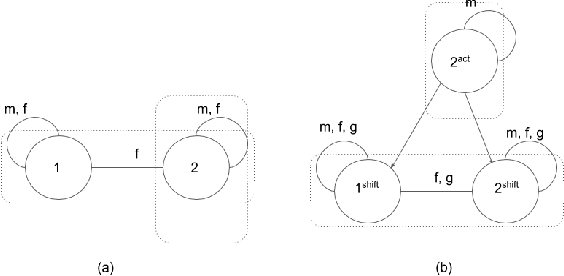
Though a lot of work in multi-agent systems is focused on reasoning about knowledge and beliefs of artificial agents, an explicit representation and reasoning about the presence/absence of agents, especially in the scenarios where agents may be unaware of other agents joining in or going offline in a multi-agent system, leading to partial knowledge/asymmetric knowledge of the agents is mostly overlooked by the MAS community. Such scenarios lay the foundations of cases where an agent can influence other agents' mental states by (mis)informing them about the presence/absence of collaborators or adversaries. In this paper, we investigate how Kripke structure-based epistemic models can be extended to express the above notion based on an agent's subjective knowledge and we discuss the challenges that come along.
Learning and Tuning Meta-heuristics in Plan Space Planning
Apr 24, 2016



In recent years, the planning community has observed that techniques for learning heuristic functions have yielded improvements in performance. One approach is to use offline learning to learn predictive models from existing heuristics in a domain dependent manner. These learned models are deployed as new heuristic functions. The learned models can in turn be tuned online using a domain independent error correction approach to further enhance their informativeness. The online tuning approach is domain independent but instance specific, and contributes to improved performance for individual instances as planning proceeds. Consequently it is more effective in larger problems. In this paper, we mention two approaches applicable in Partial Order Causal Link (POCL) Planning that is also known as Plan Space Planning. First, we endeavor to enhance the performance of a POCL planner by giving an algorithm for supervised learning. Second, we then discuss an online error minimization approach in POCL framework to minimize the step-error associated with the offline learned models thus enhancing their informativeness. Our evaluation shows that the learning approaches scale up the performance of the planner over standard benchmarks, specially for larger problems.