 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency and temporal convolutional attention for text-independent speaker recognition
Oct 19, 2019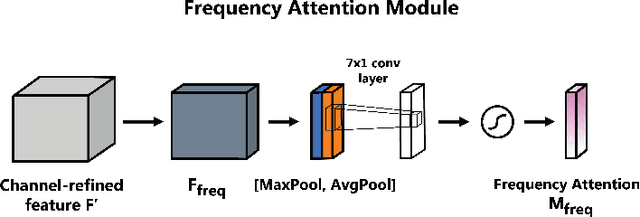
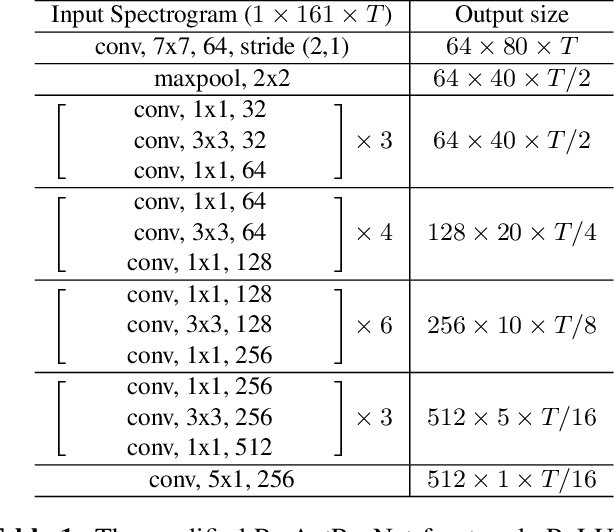
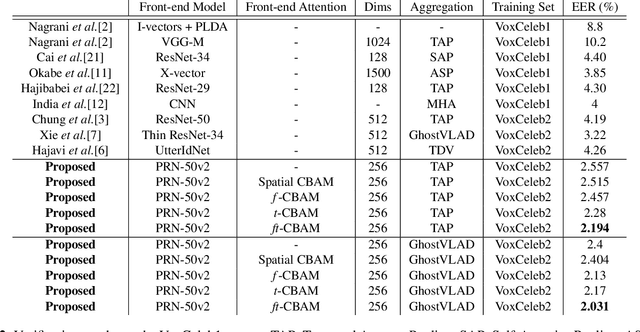
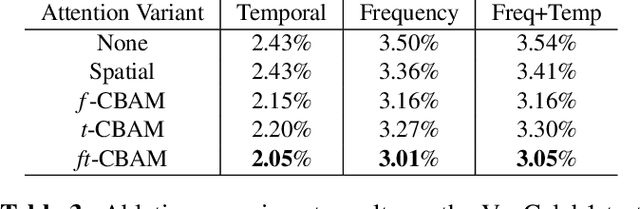
Majority of the recent approaches for text-independent speaker recognition apply attention or similar techniques for aggregation of frame-level feature descriptors generated by a deep neural network (DNN) front-end. In this paper, we propose methods of convolutional attention for independently modelling temporal and frequency information in a convolutional neural network (CNN) based front-end. Our system utilizes convolutional block attention modules (CBAMs) [1] appropriately modified to accommodate spectrogram inputs. The proposed CNN front-end fitted with the proposed convolutional attention modules outperform the no-attention and spatial-CBAM baselines by a significant margin on the VoxCeleb [2, 3] speaker verification benchmark, and our best model achieves an equal error rate of 2:031% on the VoxCeleb1 test set, improving the existing state of the art result by a significant margin. For a more thorough assessment of the effects of frequency and temporal attention in real-world conditions, we conduct ablation experiments by randomly dropping frequency bins and temporal frames from the input spectrograms, concluding that instead of modelling either of the entities, simultaneously modelling temporal and frequency attention translates to better real-world performance.
Diversity in Fashion Recommendation using Semantic Parsing
Oct 18, 2019
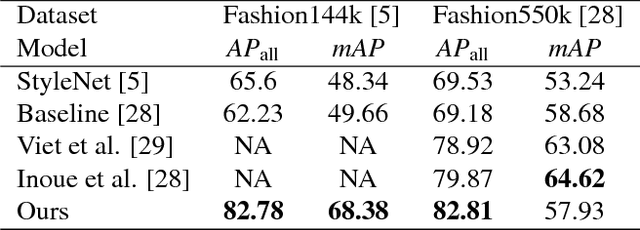
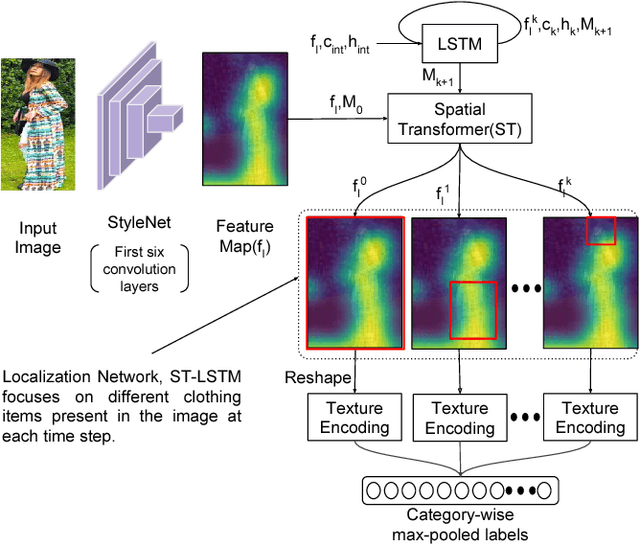

Developing recommendation system for fashion images is challenging due to the inherent ambiguity associated with what criterion a user is looking at. Suggesting multiple images where each output image is similar to the query image on the basis of a different feature or part is one way to mitigate the problem. Existing works for fashion recommendation have used Siamese or Triplet network to learn features between a similar pair and a similar-dissimilar triplet respectively. However, these methods do not provide basic information such as, how two clothing images are similar, or which parts present in the two images make them similar. In this paper, we propose to recommend images by explicitly learning and exploiting part based similarity. We propose a novel approach of learning discriminative features from weakly-supervised data by using visual attention over the parts and a texture encoding network. We show that the learned features surpass the state-of-the-art in retrieval task on DeepFashion dataset. We then use the proposed model to recommend fashion images having an explicit variation with respect to similarity of any of the parts.
Fingerprint Extraction Using Smartphone Camera
Aug 02, 2017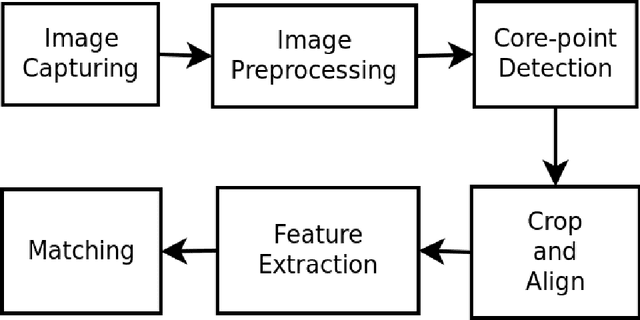
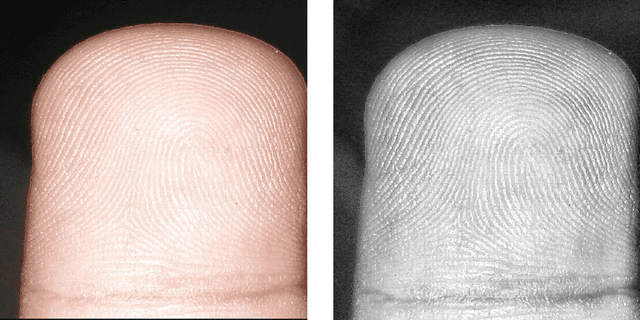
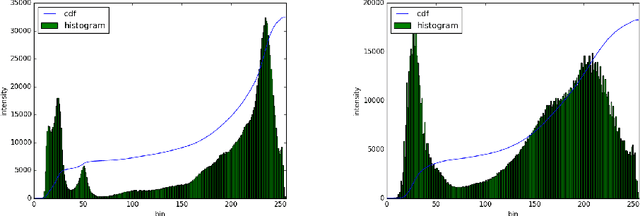
In the previous decade, there has been a considerable rise in the usage of smartphones.Due to exorbitant advancement in technology, computational speed and quality of image capturing has increased considerably. With an increase in the need for remote fingerprint verification, smartphones can be used as a powerful alternative for fingerprint authentication instead of conventional optical sensors. In this research, wepropose a technique to capture finger-images from the smartphones and pre-process them in such a way that it can be easily matched with the optical sensor images.Effective finger-image capturing, image enhancement, fingerprint pattern extraction, core point detection and image alignment techniques have been discussed. The proposed approach has been validated on FVC 2004 DB1 & DB2 dataset and the results show the efficacy of the methodology proposed. The method can be deployed for real-time commercial usage.