 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency and temporal convolutional attention for text-independent speaker recognition
Paper and Code
Oct 19, 2019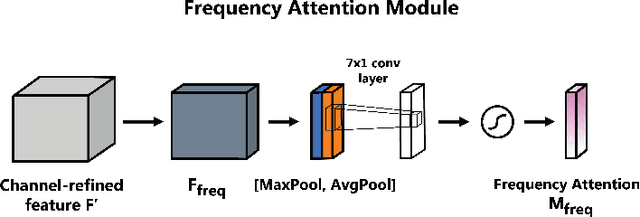
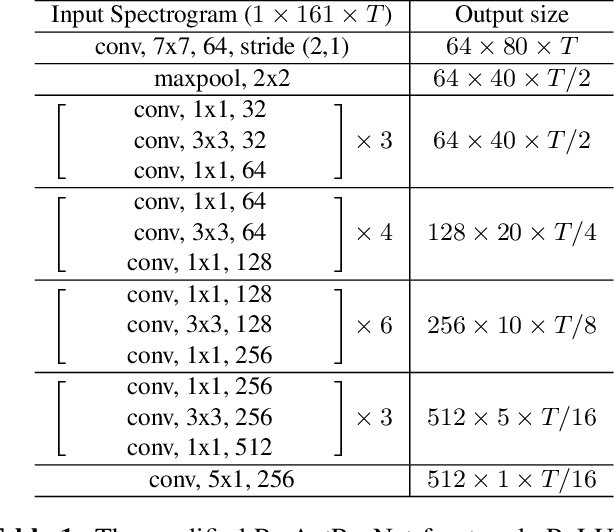
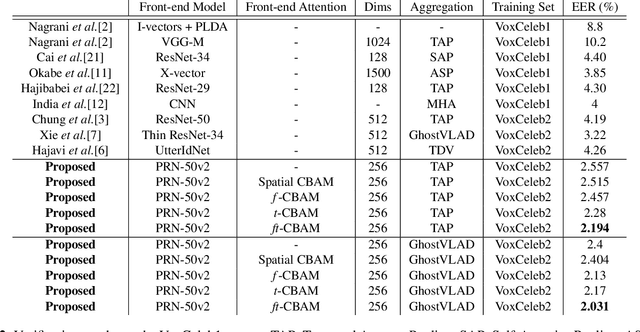
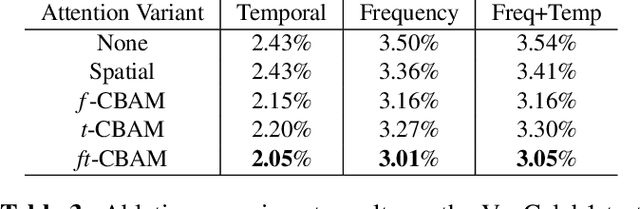
Majority of the recent approaches for text-independent speaker recognition apply attention or similar techniques for aggregation of frame-level feature descriptors generated by a deep neural network (DNN) front-end. In this paper, we propose methods of convolutional attention for independently modelling temporal and frequency information in a convolutional neural network (CNN) based front-end. Our system utilizes convolutional block attention modules (CBAMs) [1] appropriately modified to accommodate spectrogram inputs. The proposed CNN front-end fitted with the proposed convolutional attention modules outperform the no-attention and spatial-CBAM baselines by a significant margin on the VoxCeleb [2, 3] speaker verification benchmark, and our best model achieves an equal error rate of 2:031% on the VoxCeleb1 test set, improving the existing state of the art result by a significant margin. For a more thorough assessment of the effects of frequency and temporal attention in real-world conditions, we conduct ablation experiments by randomly dropping frequency bins and temporal frames from the input spectrograms, concluding that instead of modelling either of the entities, simultaneously modelling temporal and frequency attention translates to better real-world performance.