 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Pooling Strategies for Training-Free Anomalous Sound Detection with Self-Supervised Audio Embeddings
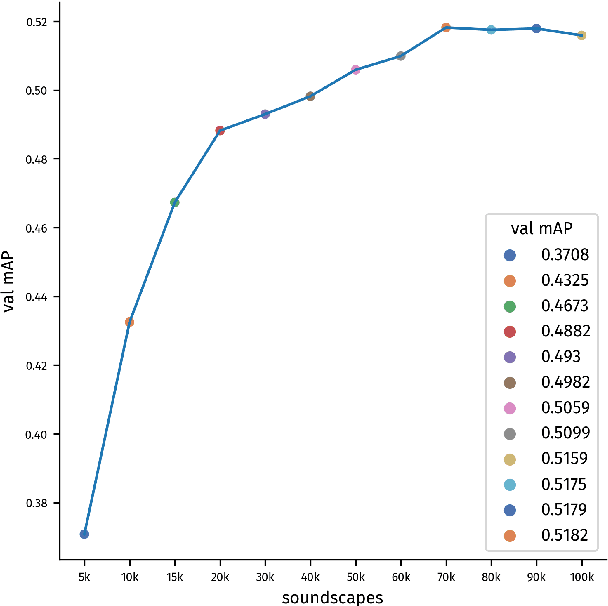
Mar 04, 2026Training-free anomalous sound detection (ASD) based on pre-trained audio embedding models has recently garnered significant attention, as it enables the detection of anomalous sounds using only normal reference data while offering improved robustness under domain shifts. However, existing embedding-based approaches almost exclusively rely on temporal mean pooling, while alternative pooling strategies have so far only been explored for spectrogram-based representations. Consequently, the role of temporal pooling in training-free ASD with pre-trained embeddings remains insufficiently understood. In this paper, we present a systematic evaluation of temporal pooling strategies across multiple state-of-the-art audio embedding models. We propose relative deviation pooling (RDP), an adaptive pooling method that emphasizes informative temporal deviations, and introduce a hybrid pooling strategy that combines RDP with generalized mean pooling. Experiments on five benchmark datasets demonstrate that the proposed methods consistently outperform mean pooling and achieve state-of-the-art performance for training-free ASD, including results that surpass all previously reported trained systems and ensembles on the DCASE2025 ASD dataset.
Audio xLSTMs: Learning Self-Supervised Audio Representations with xLSTMs
Sep 02, 2024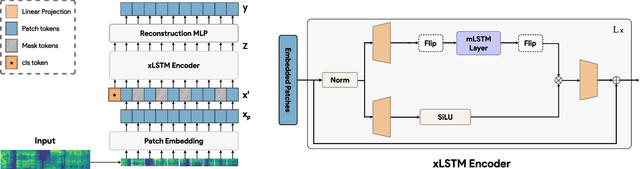
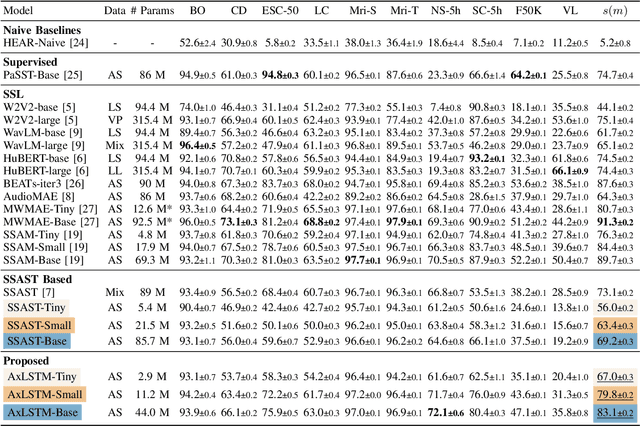
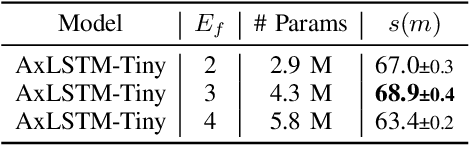
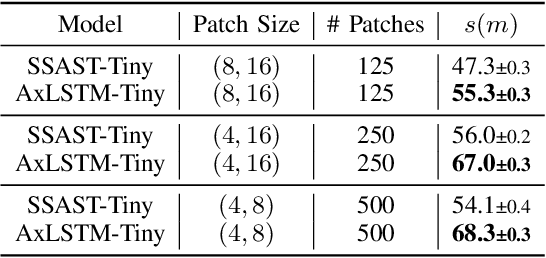
While the transformer has emerged as the eminent neural architecture, several independent lines of research have emerged to address its limitations. Recurrent neural approaches have also observed a lot of renewed interest, including the extended long short-term memory (xLSTM) architecture, which reinvigorates the original LSTM architecture. However, while xLSTMs have shown competitive performance compared to the transformer, their viability for learning self-supervised general-purpose audio representations has not yet been evaluated. This work proposes Audio xLSTM (AxLSTM), an approach to learn audio representations from masked spectrogram patches in a self-supervised setting. Pretrained on the AudioSet dataset, the proposed AxLSTM models outperform comparable self-supervised audio spectrogram transformer (SSAST) baselines by up to 20% in relative performance across a set of ten diverse downstream tasks while having up to 45% fewer parameters.
Audio Mamba: Selective State Spaces for Self-Supervised Audio Representations
Jun 04, 2024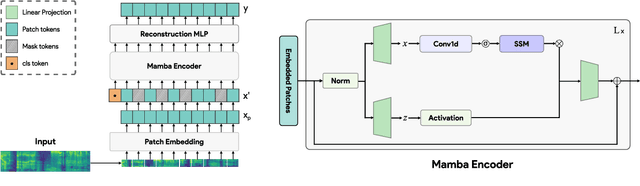
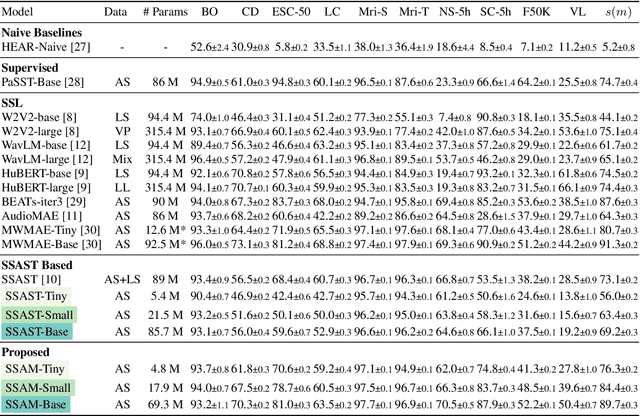
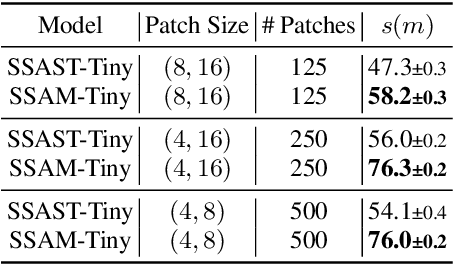
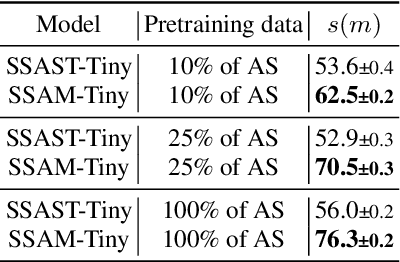
Despite its widespread adoption as the prominent neural architecture, the Transformer has spurred several independent lines of work to address its limitations. One such approach is selective state space models, which have demonstrated promising results for language modelling. However, their feasibility for learning self-supervised, general-purpose audio representations is yet to be investigated. This work proposes Audio Mamba, a selective state space model for learning general-purpose audio representations from randomly masked spectrogram patches through self-supervision. Empirical results on ten diverse audio recognition downstream tasks show that the proposed models, pretrained on the AudioSet dataset, consistently outperform comparable self-supervised audio spectrogram transformer (SSAST) baselines by a considerable margin and demonstrate better performance in dataset size, sequence length and model size comparisons.
Masked Autoencoders with Multi-Window Attention Are Better Audio Learners
Jun 01, 2023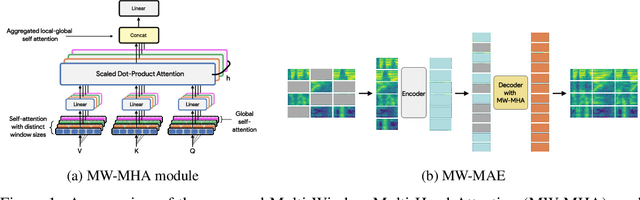
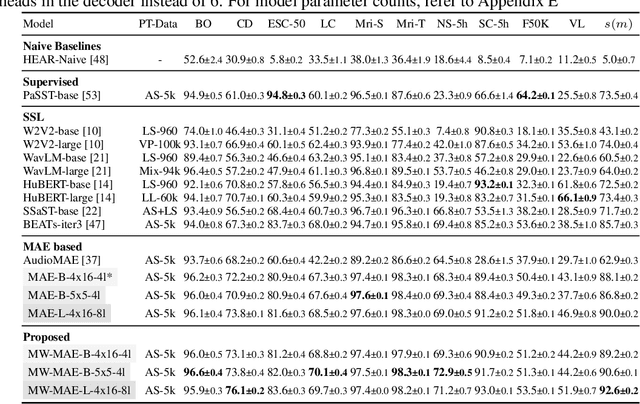
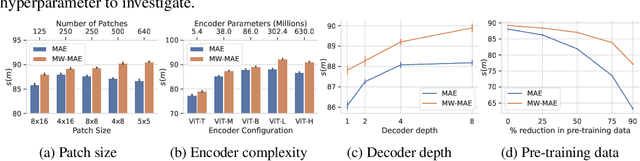
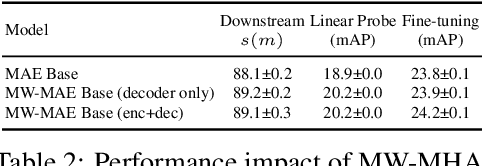
Several recent works have adapted Masked Autoencoders (MAEs) for learning general-purpose audio representations. However, they do not address two key aspects of modelling multi-domain audio data: (i) real-world audio tasks consist of a combination of local+global contexts, and (ii) real-world audio signals are complex compositions of several acoustic elements with different time-frequency characteristics. To address these concerns, this work proposes a Multi-Window Masked Autoencoder (MW-MAE) fitted with a novel Multi-Window Multi-Head Attention module that can capture information at multiple local and global contexts in every decoder transformer block through attention heads of several distinct local and global windows. Empirical results on ten downstream audio tasks show that MW-MAEs consistently outperform standard MAEs in overall performance and learn better general-purpose audio representations, as well as demonstrate considerably better scaling characteristics. Exploratory analyses of the learned representations reveals that MW-MAE encoders learn attention heads with more distinct entropies compared to those learned by MAEs, while attention heads across the different transformer blocks in MW-MAE decoders learn correlated feature representations, enabling each block to independently capture local and global information, leading to a decoupled feature hierarchy. Code for feature extraction and downstream experiments along with pre-trained weights can be found at https://github.com/10997NeurIPS23/10997_mwmae.
Learning neural audio features without supervision
Mar 29, 2022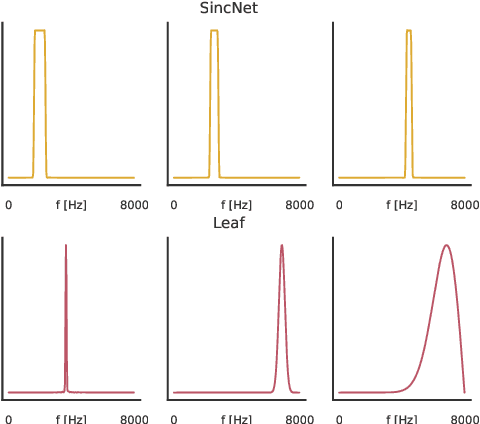
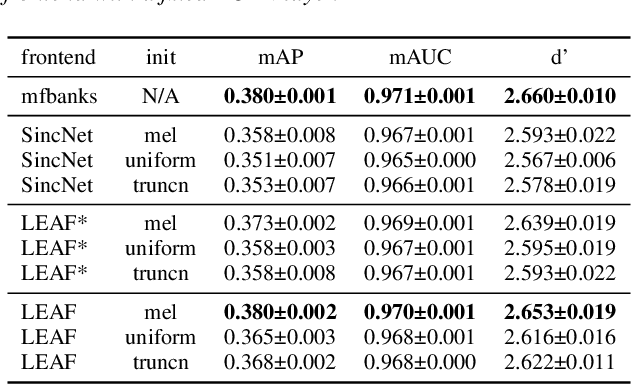
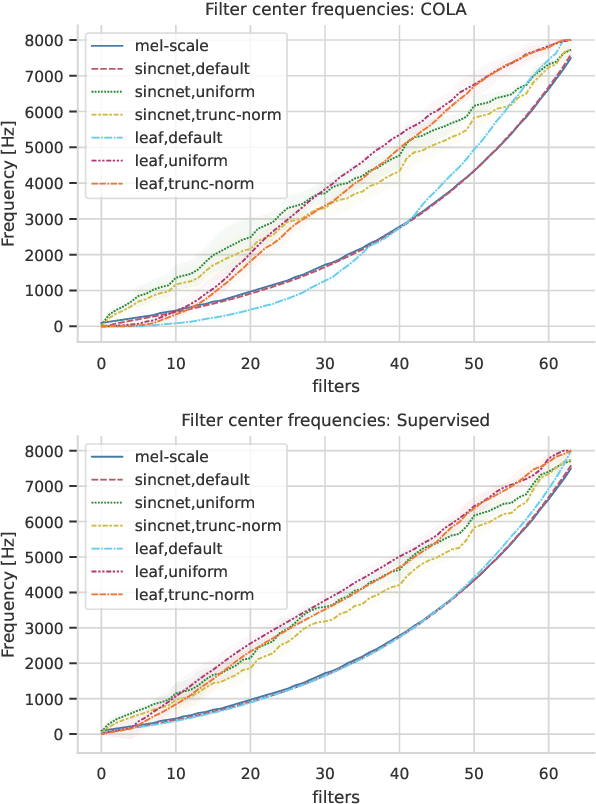
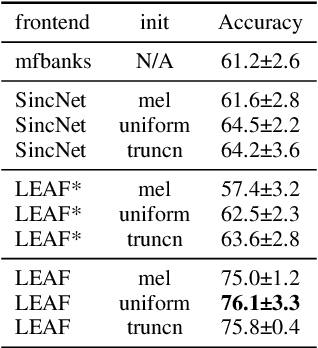
Deep audio classification, traditionally cast as training a deep neural network on top of mel-filterbanks in a supervised fashion, has recently benefited from two independent lines of work. The first one explores "learnable frontends", i.e., neural modules that produce a learnable time-frequency representation, to overcome limitations of fixed features. The second one uses self-supervised learning to leverage unprecedented scales of pre-training data. In this work, we study the feasibility of combining both approaches, i.e., pre-training learnable frontend jointly with the main architecture for downstream classification. First, we show that pretraining two previously proposed frontends (SincNet and LEAF) on Audioset drastically improves linear-probe performance over fixed mel-filterbanks, suggesting that learnable time-frequency representations can benefit self-supervised pre-training even more than supervised training. Surprisingly, randomly initialized learnable filterbanks outperform mel-scaled initialization in the self-supervised setting, a counter-intuitive result that questions the appropriateness of strong priors when designing learnable filters. Through exploratory analysis of the learned frontend components, we uncover crucial differences in properties of these frontends when used in a supervised and self-supervised setting, especially the affinity of self-supervised filters to diverge significantly from the mel-scale to model a broader range of frequencies.
GISE-51: A scalable isolated sound events dataset
Mar 23, 2021
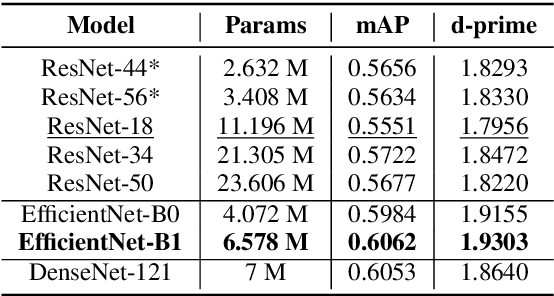

Most of the existing isolated sound event datasets comprise a small number of sound event classes, usually 10 to 15, restricted to a small domain, such as domestic and urban sound events. In this work, we introduce GISE-51, a dataset spanning 51 isolated sound events belonging to a broad domain of event types. We also release GISE-51-Mixtures, a dataset of 5-second soundscapes with hard-labelled event boundaries synthesized from GISE-51 isolated sound events. We conduct baseline sound event recognition (SER) experiments on the GISE-51-Mixtures dataset, benchmarking prominent convolutional neural networks, and models trained with the dataset demonstrate strong transfer learning performance on existing audio recognition benchmarks. Together, GISE-51 and GISE-51-Mixtures attempt to address some of the shortcomings of recent sound event datasets, providing an open, reproducible benchmark for future research along with the freedom to adapt the included isolated sound events for domain-specific applications.
Frequency and temporal convolutional attention for text-independent speaker recognition
Oct 19, 2019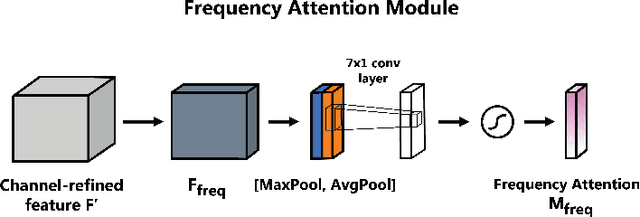
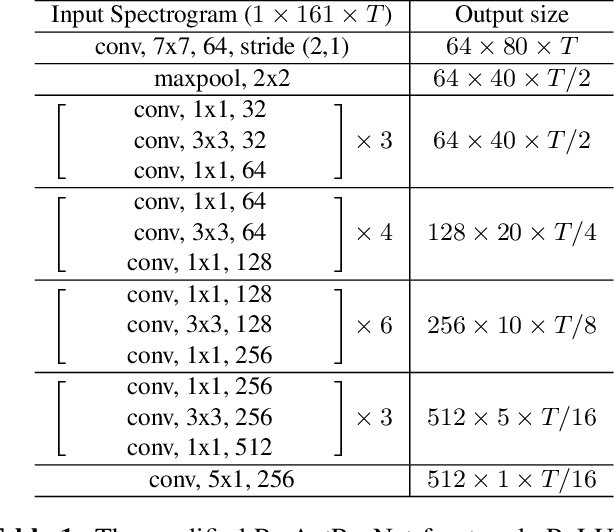
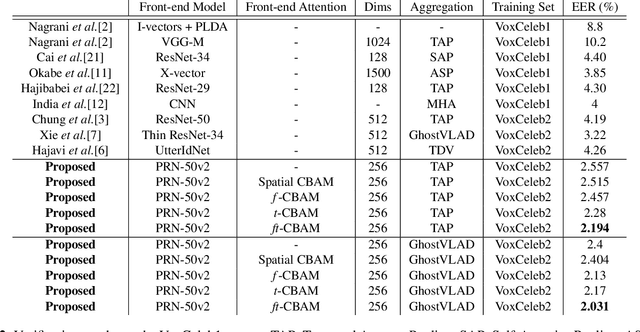
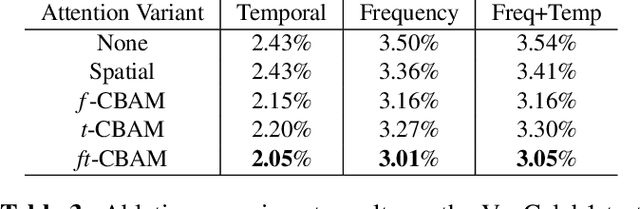
Majority of the recent approaches for text-independent speaker recognition apply attention or similar techniques for aggregation of frame-level feature descriptors generated by a deep neural network (DNN) front-end. In this paper, we propose methods of convolutional attention for independently modelling temporal and frequency information in a convolutional neural network (CNN) based front-end. Our system utilizes convolutional block attention modules (CBAMs) [1] appropriately modified to accommodate spectrogram inputs. The proposed CNN front-end fitted with the proposed convolutional attention modules outperform the no-attention and spatial-CBAM baselines by a significant margin on the VoxCeleb [2, 3] speaker verification benchmark, and our best model achieves an equal error rate of 2:031% on the VoxCeleb1 test set, improving the existing state of the art result by a significant margin. For a more thorough assessment of the effects of frequency and temporal attention in real-world conditions, we conduct ablation experiments by randomly dropping frequency bins and temporal frames from the input spectrograms, concluding that instead of modelling either of the entities, simultaneously modelling temporal and frequency attention translates to better real-world performance.