 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Mamba: Selective State Spaces for Self-Supervised Audio Representations
Paper and Code
Jun 04, 2024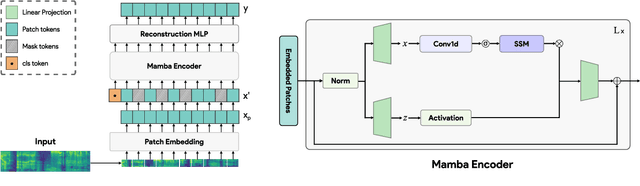
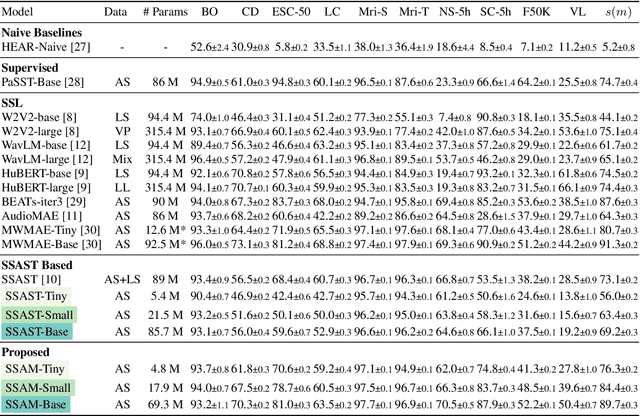
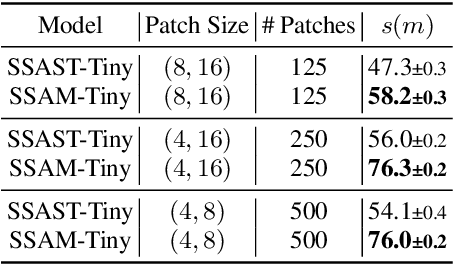
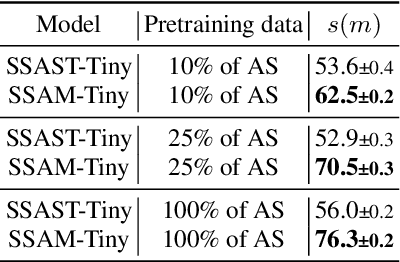
Despite its widespread adoption as the prominent neural architecture, the Transformer has spurred several independent lines of work to address its limitations. One such approach is selective state space models, which have demonstrated promising results for language modelling. However, their feasibility for learning self-supervised, general-purpose audio representations is yet to be investigated. This work proposes Audio Mamba, a selective state space model for learning general-purpose audio representations from randomly masked spectrogram patches through self-supervision. Empirical results on ten diverse audio recognition downstream tasks show that the proposed models, pretrained on the AudioSet dataset, consistently outperform comparable self-supervised audio spectrogram transformer (SSAST) baselines by a considerable margin and demonstrate better performance in dataset size, sequence length and model size comparisons.