 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Autoencoders with Multi-Window Attention Are Better Audio Learners
Paper and Code
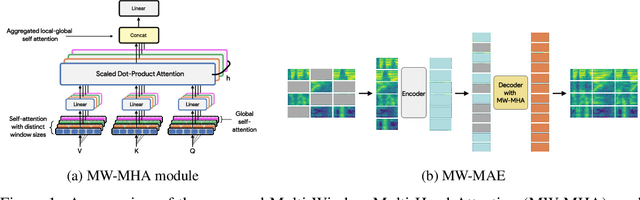
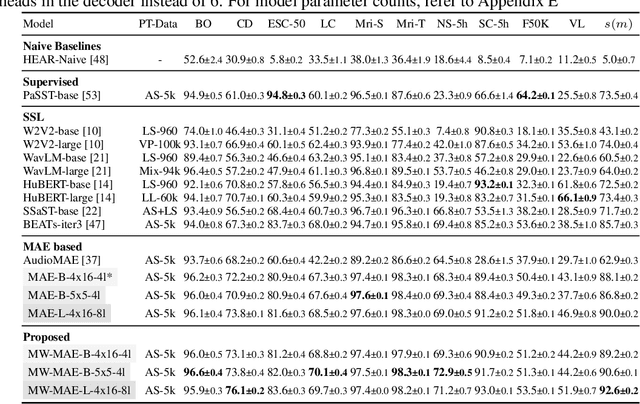
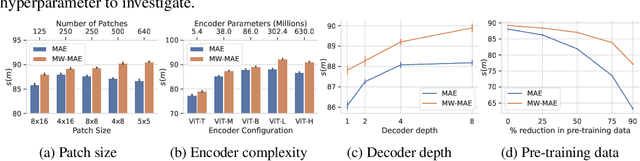
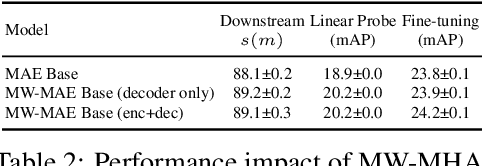
Several recent works have adapted Masked Autoencoders (MAEs) for learning general-purpose audio representations. However, they do not address two key aspects of modelling multi-domain audio data: (i) real-world audio tasks consist of a combination of local+global contexts, and (ii) real-world audio signals are complex compositions of several acoustic elements with different time-frequency characteristics. To address these concerns, this work proposes a Multi-Window Masked Autoencoder (MW-MAE) fitted with a novel Multi-Window Multi-Head Attention module that can capture information at multiple local and global contexts in every decoder transformer block through attention heads of several distinct local and global windows. Empirical results on ten downstream audio tasks show that MW-MAEs consistently outperform standard MAEs in overall performance and learn better general-purpose audio representations, as well as demonstrate considerably better scaling characteristics. Exploratory analyses of the learned representations reveals that MW-MAE encoders learn attention heads with more distinct entropies compared to those learned by MAEs, while attention heads across the different transformer blocks in MW-MAE decoders learn correlated feature representations, enabling each block to independently capture local and global information, leading to a decoupled feature hierarchy. Code for feature extraction and downstream experiments along with pre-trained weights can be found at https://github.com/10997NeurIPS23/10997_mwmae.