 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Training in Pommerman with Imitation and Reinforcement Learning
Paper and Code


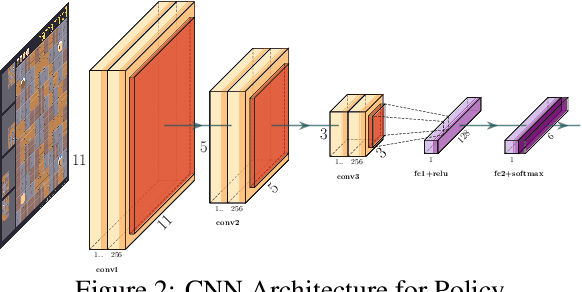

The Pommerman simulation was recently developed to mimic the classic Japanese game Bomberman, and focuses on competitive gameplay in a multi-agent setting. We focus on the 2$\times$2 team version of Pommerman, developed for a competition at NeurIPS 2018. Our methodology involves training an agent initially through imitation learning on a noisy expert policy, followed by a proximal-policy optimization (PPO) reinforcement learning algorithm. The basic PPO approach is modified for stable transition from the imitation learning phase through reward shaping, action filters based on heuristics, and curriculum learning. The proposed methodology is able to beat heuristic and pure reinforcement learning baselines with a combined 100,000 training games, significantly faster than other non-tree-search methods in literature. We present results against multiple agents provided by the developers of the simulation, including some that we have enhanced. We include a sensitivity analysis over different parameters, and highlight undesirable effects of some strategies that initially appear promising. Since Pommerman is a complex multi-agent competitive environment, the strategies developed here provide insights into several real-world problems with characteristics such as partial observability, decentralized execution (without communication), and very sparse and delayed rewards.