 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIBRE: Self Improvement Based REwards for Reinforcement Learning
Apr 22, 2020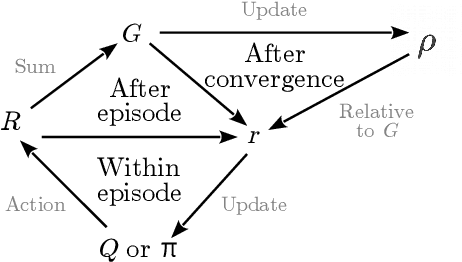
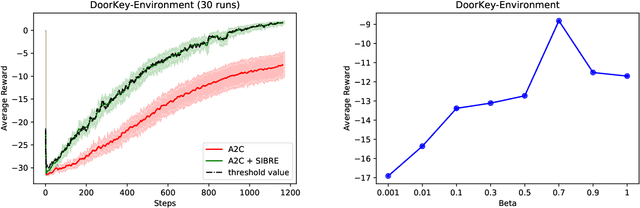
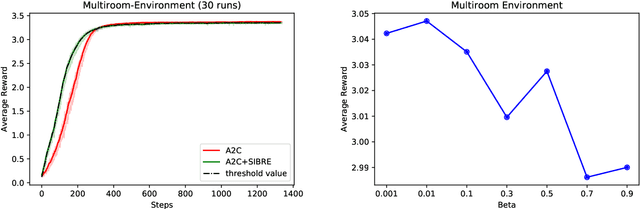
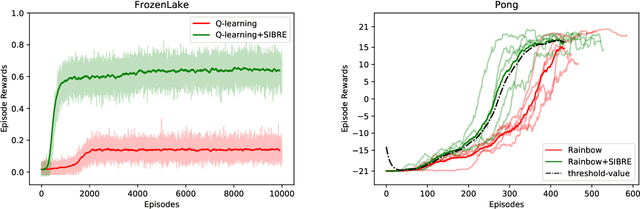
We propose a generic reward shaping approach for improving rate of convergence in reinforcement learning (RL), called Self Improvement Based REwards, or SIBRE. The approach can be used for episodic environments in conjunction with any existing RL algorithm, and consists of rewarding improvement over the agent's own past performance. We show that SIBRE converges under the same conditions as the algorithm whose reward has been modified. The new rewards help discriminate between policies when the original rewards are either weakly discriminated or sparse. Experiments show that in certain environments, this approach speeds up learning and converges to the optimal policy faster. We analyse SIBRE theoretically, and follow it up with tests on several well-known benchmark environments for reinforcement learning.