 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssigning Credit with Partial Reward Decoupling in Multi-Agent Proximal Policy Optimization
Aug 08, 2024Multi-agent proximal policy optimization (MAPPO) has recently demonstrated state-of-the-art performance on challenging multi-agent reinforcement learning tasks. However, MAPPO still struggles with the credit assignment problem, wherein the sheer difficulty in ascribing credit to individual agents' actions scales poorly with team size. In this paper, we propose a multi-agent reinforcement learning algorithm that adapts recent developments in credit assignment to improve upon MAPPO. Our approach leverages partial reward decoupling (PRD), which uses a learned attention mechanism to estimate which of a particular agent's teammates are relevant to its learning updates. We use this estimate to dynamically decompose large groups of agents into smaller, more manageable subgroups. We empirically demonstrate that our approach, PRD-MAPPO, decouples agents from teammates that do not influence their expected future reward, thereby streamlining credit assignment. We additionally show that PRD-MAPPO yields significantly higher data efficiency and asymptotic performance compared to both MAPPO and other state-of-the-art methods across several multi-agent tasks, including StarCraft II. Finally, we propose a version of PRD-MAPPO that is applicable to \textit{shared} reward settings, where PRD was previously not applicable, and empirically show that this also leads to performance improvements over MAPPO.
Learning Cooperative Multi-Agent Policies with Partial Reward Decoupling
Dec 23, 2021

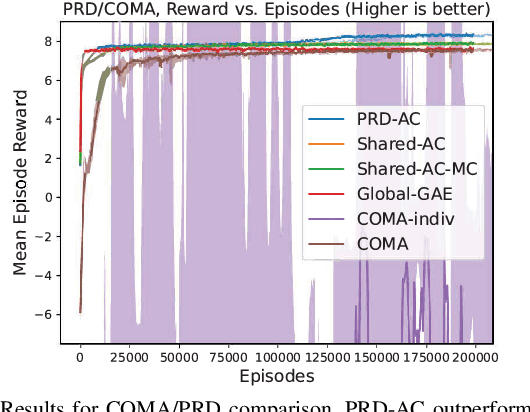

One of the preeminent obstacles to scaling multi-agent reinforcement learning to large numbers of agents is assigning credit to individual agents' actions. In this paper, we address this credit assignment problem with an approach that we call \textit{partial reward decoupling} (PRD), which attempts to decompose large cooperative multi-agent RL problems into decoupled subproblems involving subsets of agents, thereby simplifying credit assignment. We empirically demonstrate that decomposing the RL problem using PRD in an actor-critic algorithm results in lower variance policy gradient estimates, which improves data efficiency, learning stability, and asymptotic performance across a wide array of multi-agent RL tasks, compared to various other actor-critic approaches. Additionally, we relate our approach to counterfactual multi-agent policy gradient (COMA), a state-of-the-art MARL algorithm, and empirically show that our approach outperforms COMA by making better use of information in agents' reward streams, and by enabling recent advances in advantage estimation to be used.