 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethodology for a Statistical Analysis of Influencing Factors on 3D Object Detection Performance
Nov 13, 2024

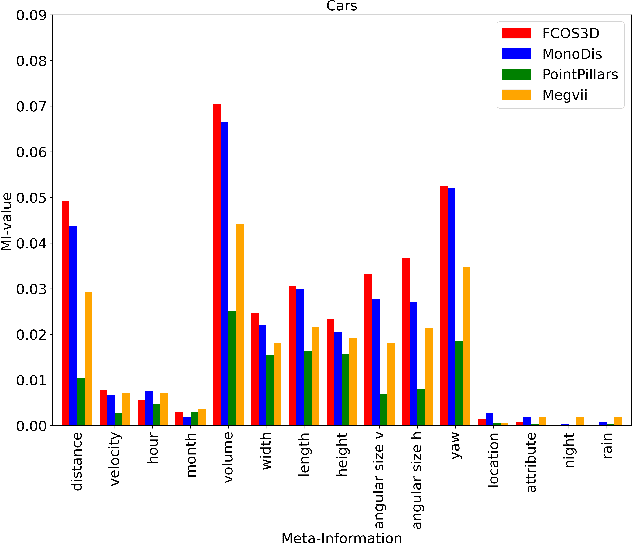
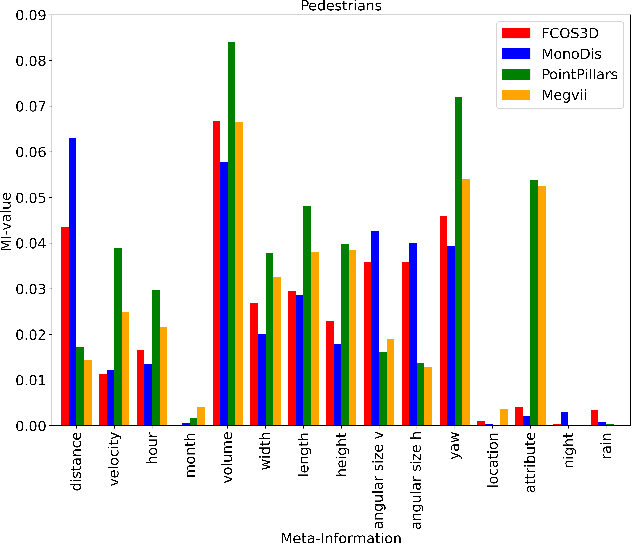
In autonomous driving, object detection is an essential task to perceive the environment by localizing and classifying objects. Most object detection algorithms rely on deep learning for their superior performance. However, their black box nature makes it challenging to ensure safety. In this paper, we propose a first-of-its-kind methodology for statistical analysis of the influence of various factors related to the objects to detect or the environment on the detection performance of both LiDAR- and camera-based 3D object detectors. We perform a univariate analysis between each of the factors and the detection error in order to compare the strength of influence. To better identify potential sources of detection errors, we also analyze the performance in dependency of the influencing factors and examine the interdependencies between the different influencing factors. Recognizing the factors that influence detection performance helps identify robustness issues in the trained object detector and supports the safety approval of object detection systems.
Explainable AI for Safe and Trustworthy Autonomous Driving: A Systematic Review
Feb 08, 2024



Artificial Intelligence (AI) shows promising applications for the perception and planning tasks in autonomous driving (AD) due to its superior performance compared to conventional methods. However, inscrutable AI systems exacerbate the existing challenge of safety assurance of AD. One way to mitigate this challenge is to utilize explainable AI (XAI) techniques. To this end, we present the first comprehensive systematic literature review of explainable methods for safe and trustworthy AD. We begin by analyzing the requirements for AI in the context of AD, focusing on three key aspects: data, model, and agency. We find that XAI is fundamental to meeting these requirements. Based on this, we explain the sources of explanations in AI and describe a taxonomy of XAI. We then identify five key contributions of XAI for safe and trustworthy AI in AD, which are interpretable design, interpretable surrogate models, interpretable monitoring, auxiliary explanations, and interpretable validation. Finally, we propose a modular framework called SafeX to integrate these contributions, enabling explanation delivery to users while simultaneously ensuring the safety of AI models.