 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Gradients in Non-Stationary Environments
Paper and Code
Sep 13, 2022
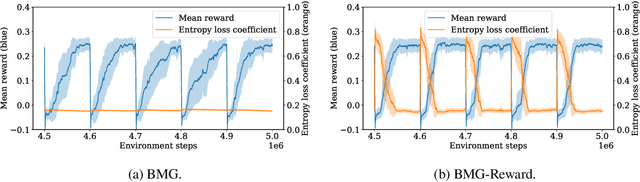
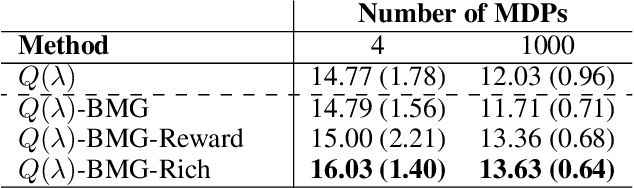
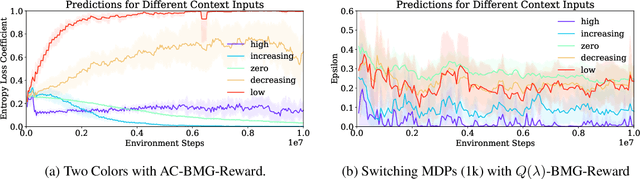
Meta-gradient methods (Xu et al., 2018; Zahavy et al., 2020) offer a promising solution to the problem of hyperparameter selection and adaptation in non-stationary reinforcement learning problems. However, the properties of meta-gradients in such environments have not been systematically studied. In this work, we bring new clarity to meta-gradients in non-stationary environments. Concretely, we ask: (i) how much information should be given to the learned optimizers, so as to enable faster adaptation and generalization over a lifetime, (ii) what meta-optimizer functions are learned in this process, and (iii) whether meta-gradient methods provide a bigger advantage in highly non-stationary environments. To study the effect of information provided to the meta-optimizer, as in recent works (Flennerhag et al., 2021; Almeida et al., 2021), we replace the tuned meta-parameters of fixed update rules with learned meta-parameter functions of selected context features. The context features carry information about agent performance and changes in the environment and hence can inform learned meta-parameter schedules. We find that adding more contextual information is generally beneficial, leading to faster adaptation of meta-parameter values and increased performance over a lifetime. We support these results with a qualitative analysis of resulting meta-parameter schedules and learned functions of context features. Lastly, we find that without context, meta-gradients do not provide a consistent advantage over the baseline in highly non-stationary environments. Our findings suggest that contextualizing meta-gradients can play a pivotal role in extracting high performance from meta-gradients in non-stationary settings.