 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Modal Prototype Joint Learning for Compositional Zero-Shot Learning
Paper and Code
Jan 23, 2025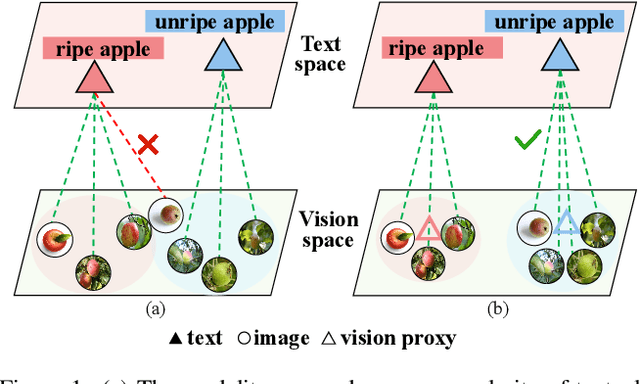

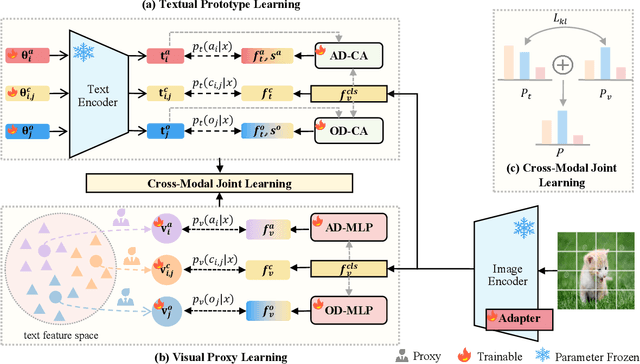
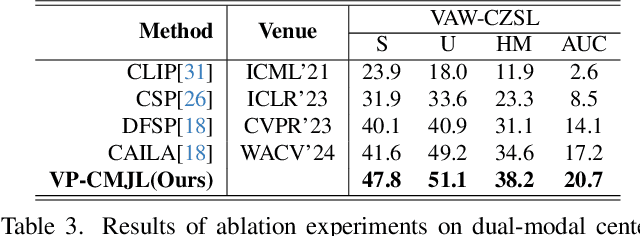
Compositional Zero-Shot Learning (CZSL) aims to recognize novel compositions of attributes and objects by leveraging knowledge learned from seen compositions. Recent approaches have explored the use of Vision-Language Models (VLMs) to align textual and visual modalities. These methods typically employ prompt engineering, parameter-tuning, and modality fusion to generate rich textual prototypes that serve as class prototypes for CZSL. However, the modality gap results in textual prototypes being unable to fully capture the optimal representations of all class prototypes, particularly those with fine-grained features, which can be directly obtained from the visual modality. In this paper, we propose a novel Dual-Modal Prototype Joint Learning framework for the CZSL task. Our approach, based on VLMs, introduces prototypes in both the textual and visual modalities. The textual prototype is optimized to capture broad conceptual information, aiding the model's generalization across unseen compositions. Meanwhile, the visual prototype is used to mitigate the classification errors caused by the modality gap and capture fine-grained details to distinguish images with similar appearances. To effectively optimize these prototypes, we design specialized decomposition modules and a joint learning strategy that enrich the features from both modalities. These prototypes not only capture key category information during training but also serve as crucial reference targets during inference. Experimental results demonstrate that our approach achieves state-of-the-art performance in the closed-world setting and competitive performance in the open-world setting across three publicly available CZSL benchmarks. These findings validate the effectiveness of our method in advancing compositional generalization.