 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategies for political-statement segmentation and labelling in unstructured text
Paper and Code
Mar 10, 2025
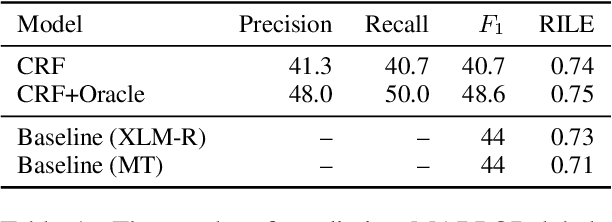
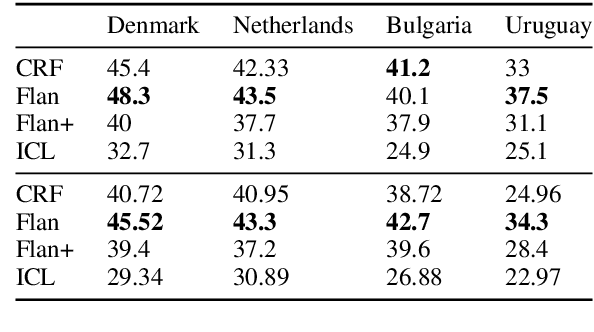
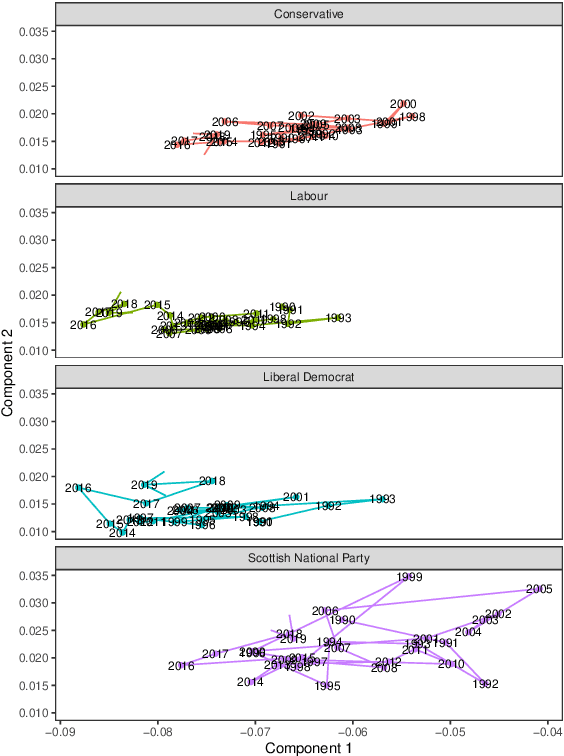
Analysis of parliamentary speeches and political-party manifestos has become an integral area of computational study of political texts. While speeches have been overwhelmingly analysed using unsupervised methods, a large corpus of manifestos with by-statement political-stance labels has been created by the participants of the MARPOR project. It has been recently shown that these labels can be predicted by a neural model; however, the current approach relies on provided statement boundaries, limiting out-of-domain applicability. In this work, we propose and test a range of unified split-and-label frameworks -- based on linear-chain CRFs, fine-tuned text-to-text models, and the combination of in-context learning with constrained decoding -- that can be used to jointly segment and classify statements from raw textual data. We show that our approaches achieve competitive accuracy when applied to raw text of political manifestos, and then demonstrate the research potential of our method by applying it to the records of the UK House of Commons and tracing the political trajectories of four major parties in the last three decades.