 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier identification in Ancient Egyptian as a low-resource sequence-labelling task
Paper and Code

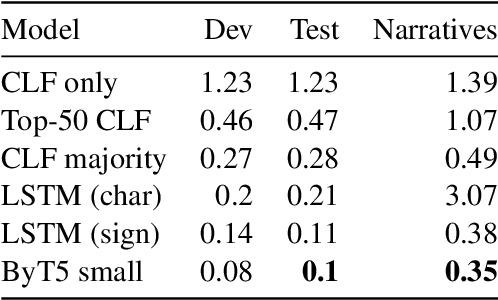

The complex Ancient Egyptian (AE) writing system was characterised by widespread use of graphemic classifiers (determinatives): silent (unpronounced) hieroglyphic signs clarifying the meaning or indicating the pronunciation of the host word. The study of classifiers has intensified in recent years with the launch and quick growth of the iClassifier project, a web-based platform for annotation and analysis of classifiers in ancient and modern languages. Thanks to the data contributed by the project participants, it is now possible to formulate the identification of classifiers in AE texts as an NLP task. In this paper, we make first steps towards solving this task by implementing a series of sequence-labelling neural models, which achieve promising performance despite the modest amount of training data. We discuss tokenisation and operationalisation issues arising from tackling AE texts and contrast our approach with frequency-based baselines.