 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Learning Capabilities of Language Models using LEVERWORLDS
Paper and Code
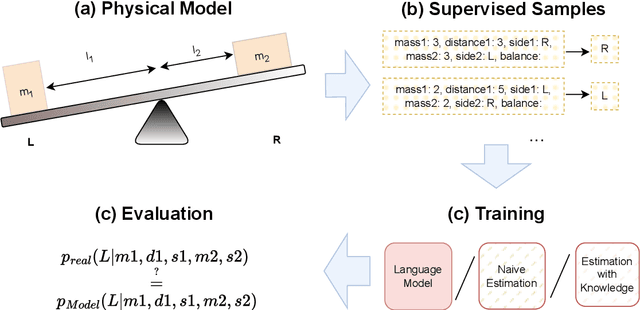
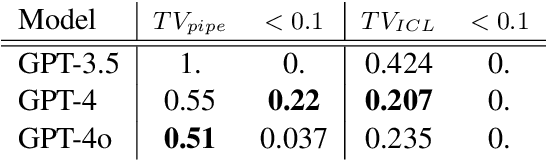
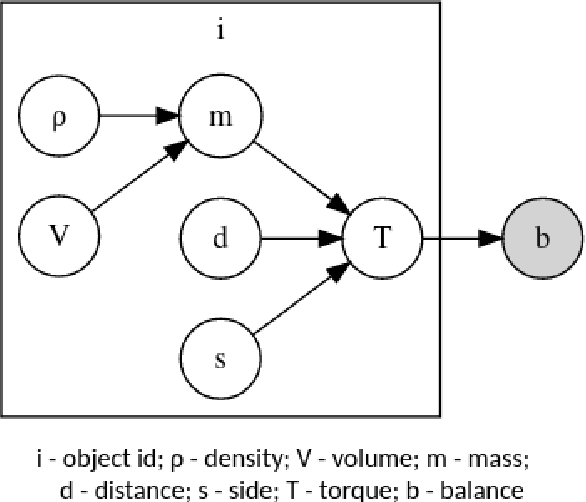
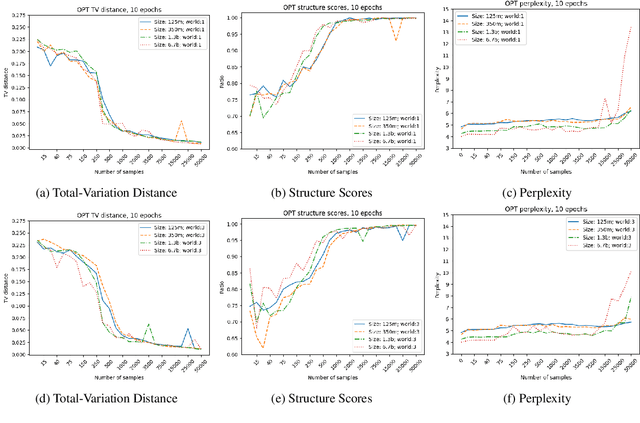
Learning a model of a stochastic setting often involves learning both general structure rules and specific properties of the instance. This paper investigates the interplay between learning the general and the specific in various learning methods, with emphasis on sample efficiency. We design a framework called {\sc LeverWorlds}, which allows the generation of simple physics-inspired worlds that follow a similar generative process with different distributions, and their instances can be expressed in natural language. These worlds allow for controlled experiments to assess the sample complexity of different learning methods. We experiment with classic learning algorithms as well as Transformer language models, both with fine-tuning and In-Context Learning (ICL). Our general finding is that (1) Transformers generally succeed in the task; but (2) they are considerably less sample efficient than classic methods that make stronger assumptions about the structure, such as Maximum Likelihood Estimation and Logistic Regression. This finding is in tension with the recent tendency to use Transformers as general-purpose estimators. We propose an approach that leverages the ICL capabilities of contemporary language models to apply simple algorithms for this type of data. Our experiments show that models currently struggle with the task but show promising potential.