 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlamming: Training a Speech Language Model on One GPU in a Day
Feb 19, 2025


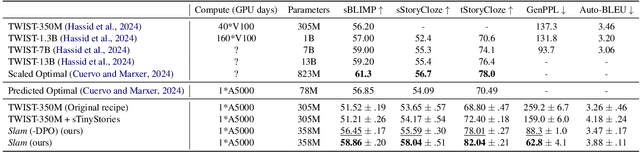
We introduce Slam, a recipe for training high-quality Speech Language Models (SLMs) on a single academic GPU in 24 hours. We do so through empirical analysis of model initialisation and architecture, synthetic training data, preference optimisation with synthetic data and tweaking all other components. We empirically demonstrate that this training recipe also scales well with more compute getting results on par with leading SLMs in a fraction of the compute cost. We hope these insights will make SLM training and research more accessible. In the context of SLM scaling laws, our results far outperform predicted compute optimal performance, giving an optimistic view to SLM feasibility. See code, data, models, samples at - https://pages.cs.huji.ac.il/adiyoss-lab/slamming .
Unsupervised Speech Segmentation: A General Approach Using Speech Language Models
Jan 07, 2025



In this paper, we introduce an unsupervised approach for Speech Segmentation, which builds on previously researched approaches, e.g., Speaker Diarization, while being applicable to an inclusive set of acoustic-semantic distinctions, paving a path towards a general Unsupervised Speech Segmentation approach. Unlike traditional speech and audio segmentation, which mainly focuses on spectral changes in the input signal, e.g., phone segmentation, our approach tries to segment the spoken utterance into chunks with differing acoustic-semantic styles, focusing on acoustic-semantic information that does not translate well into text, e.g., emotion or speaker. While most Speech Segmentation tasks only handle one style change, e.g., emotion diarization, our approach tries to handle multiple acoustic-semantic style changes. Leveraging recent advances in Speech Language Models (SLMs), we propose a simple unsupervised method to segment a given speech utterance. We empirically demonstrate the effectiveness of the proposed approach by considering several setups. Results suggest that the proposed method is superior to the evaluated baselines on boundary detection, segment purity, and over-segmentation. Code is available at https://github.com/avishaiElmakies/unsupervised_speech_segmentation_using_slm.