 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Magic Correlations: Understanding Knowledge Transfer from Pretraining to Supervised Fine-Tuning
Feb 11, 2026Understanding how language model capabilities transfer from pretraining to supervised fine-tuning (SFT) is fundamental to efficient model development and data curation. In this work, we investigate four core questions: RQ1. To what extent do accuracy and confidence rankings established during pretraining persist after SFT? RQ2. Which benchmarks serve as robust cross-stage predictors and which are unreliable? RQ3. How do transfer dynamics shift with model scale? RQ4. How well does model confidence align with accuracy, as a measure of calibration quality? Does this alignment pattern transfer across training stages? We address these questions through a suite of correlation protocols applied to accuracy and confidence metrics across diverse data mixtures and model scales. Our experiments reveal that transfer reliability varies dramatically across capability categories, benchmarks, and scales -- with accuracy and confidence exhibiting distinct, sometimes opposing, scaling dynamics. These findings shed light on the complex interplay between pretraining decisions and downstream outcomes, providing actionable guidance for benchmark selection, data curation, and efficient model development.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Not Every AI Problem is a Data Problem: We Should Be Intentional About Data Scaling
Jan 23, 2025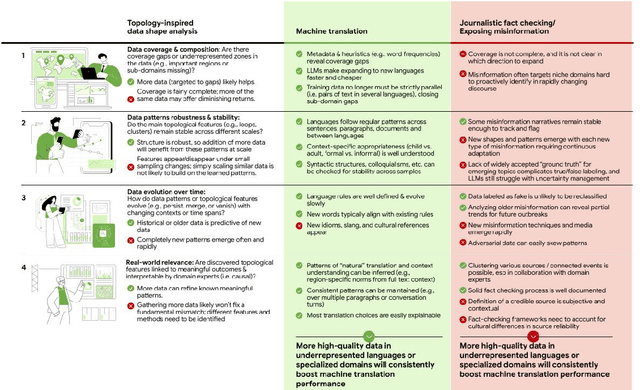
While Large Language Models require more and more data to train and scale, rather than looking for any data to acquire, we should consider what types of tasks are more likely to benefit from data scaling. We should be intentional in our data acquisition. We argue that the topology of data itself informs which tasks to prioritize in data scaling, and shapes the development of the next generation of compute paradigms for tasks where data scaling is inefficient, or even insufficient.
Relationships are Complicated! An Analysis of Relationships Between Datasets on the Web
Aug 26, 2024The Web today has millions of datasets, and the number of datasets continues to grow at a rapid pace. These datasets are not standalone entities; rather, they are intricately connected through complex relationships. Semantic relationships between datasets provide critical insights for research and decision-making processes. In this paper, we study dataset relationships from the perspective of users who discover, use, and share datasets on the Web: what relationships are important for different tasks? What contextual information might users want to know? We first present a comprehensive taxonomy of relationships between datasets on the Web and map these relationships to user tasks performed during dataset discovery. We develop a series of methods to identify these relationships and compare their performance on a large corpus of datasets generated from Web pages with schema.org markup. We demonstrate that machine-learning based methods that use dataset metadata achieve multi-class classification accuracy of 90%. Finally, we highlight gaps in available semantic markup for datasets and discuss how incorporating comprehensive semantics can facilitate the identification of dataset relationships. By providing a comprehensive overview of dataset relationships at scale, this paper sets a benchmark for future research.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.