 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Region of Interest in Human Visual Search Based on Statistical Texture and Gabor Features
Jan 12, 2026Understanding human visual search behavior is a fundamental problem in vision science and computer vision, with direct implications for modeling how observers allocate attention in location-unknown search tasks. In this study, we investigate the relationship between Gabor-based features and gray-level co-occurrence matrix (GLCM) based texture features in modeling early-stage visual search behavior. Two feature-combination pipelines are proposed to integrate Gabor and GLCM features for narrowing the region of possible human fixations. The pipelines are evaluated using simulated digital breast tomosynthesis images. Results show qualitative agreement among fixation candidates predicted by the proposed pipelines and a threshold-based model observer. A strong correlation is observed between GLCM mean and Gabor feature responses, indicating that these features encode related image information despite their different formulations. Eye-tracking data from human observers further suggest consistency between predicted fixation regions and early-stage gaze behavior. These findings highlight the value of combining structural and texture-based features for modeling visual search and support the development of perceptually informed observer models.
VENOM: A Vectorized N:M Format for Unleashing the Power of Sparse Tensor Cores
Oct 03, 2023



The increasing success and scaling of Deep Learning models demands higher computational efficiency and power. Sparsification can lead to both smaller models as well as higher compute efficiency, and accelerated hardware is becoming available. However, exploiting it efficiently requires kernel implementations, pruning algorithms, and storage formats, to utilize hardware support of specialized sparse vector units. An example of those are the NVIDIA's Sparse Tensor Cores (SPTCs), which promise a 2x speedup. However, SPTCs only support the 2:4 format, limiting achievable sparsity ratios to 50%. We present the V:N:M format, which enables the execution of arbitrary N:M ratios on SPTCs. To efficiently exploit the resulting format, we propose Spatha, a high-performance sparse-library for DL routines. We show that Spatha achieves up to 37x speedup over cuBLAS. We also demonstrate a second-order pruning technique that enables sparsification to high sparsity ratios with V:N:M and little to no loss in accuracy in modern transformers.
Reusing Trained Layers of Convolutional Neural Networks to Shorten Hyperparameters Tuning Time
Jun 16, 2020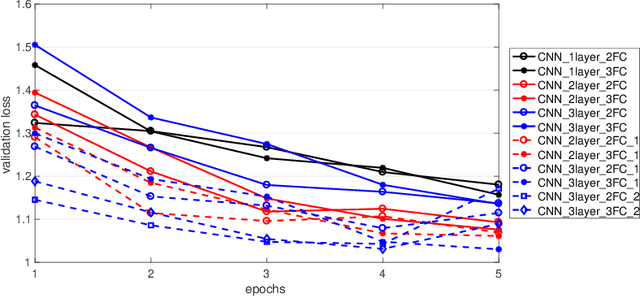

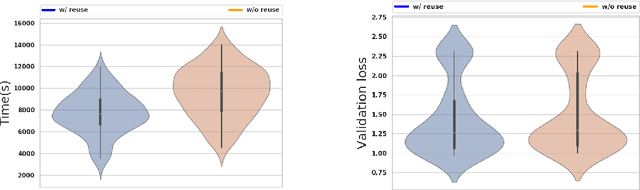
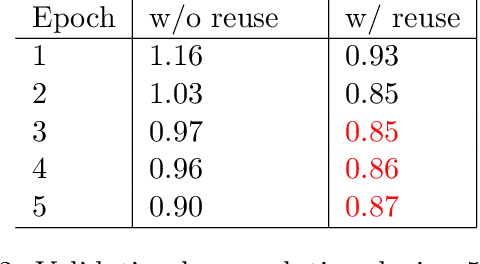
Hyperparameters tuning is a time-consuming approach, particularly when the architecture of the neural network is decided as part of this process. For instance, in convolutional neural networks (CNNs), the selection of the number and the characteristics of the hidden (convolutional) layers may be decided. This implies that the search process involves the training of all these candidate network architectures. This paper describes a proposal to reuse the weights of hidden (convolutional) layers among different trainings to shorten this process. The rationale is that if a set of convolutional layers have been trained to solve a given problem, the weights calculated in this training may be useful when a new convolutional layer is added to the network architecture. This idea has been tested using the CIFAR-10 dataset, testing different CNNs architectures with up to 3 convolutional layers and up to 3 fully connected layers. The experiments compare the training time and the validation loss when reusing and not reusing convolutional layers. They confirm that this strategy reduces the training time while it even increases the accuracy of the resulting neural network. This finding opens up the future possibility of integrating this strategy in existing AutoML methods with the purpose of reducing the total search time.
A Hybrid Approach for Tracking Individual Players in Broadcast Match Videos
Mar 10, 2020

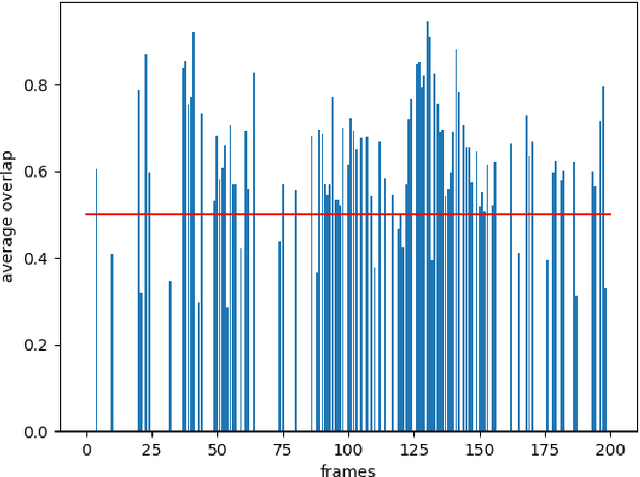
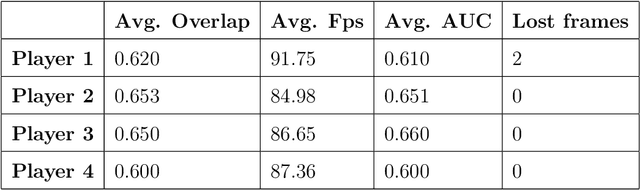
Tracking people in a video sequence is a challenging task that has been approached from many perspectives. This task becomes even more complicated when the person to track is a player in a broadcasted sport event, the reasons being the existence of difficulties such as frequent camera movements or switches, total and partial occlusions between players, and blurry frames due to the codification algorithm of the video. This paper introduces a player tracking solution which is both fast and accurate. This allows to track a player precisely in real-time. The approach combines several models that are executed concurrently in a relatively modest hardware, and whose accuracy has been validated against hand-labeled broadcast video sequences. Regarding the accuracy, the tests show that the area under curve (AUC) of our approach is around 0.6, which is similar to generic state of the art solutions. As for performance, our proposal can process high definition videos (1920x1080 px) at 80 fps.