 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSPO: Breaking the Double Homogenization Dilemma in Multi-turn Search Policy Optimization
Jan 30, 2026Multi-turn tool-integrated reasoning enables Large Language Models (LLMs) to solve complex tasks through iterative information retrieval. However, current reinforcement learning (RL) frameworks for search-augmented reasoning predominantly rely on sparse outcome-level rewards, leading to a "Double Homogenization Dilemma." This manifests as (1) Process homogenization, where the thinking, reasoning, and tooling involved in generation are ignored. (2) Intra-group homogenization, coarse-grained outcome rewards often lead to inefficiencies in intra-group advantage estimation with methods like Group Relative Policy Optimization (GRPO) during sampling. To address this, we propose Turn-level Stage-aware Policy Optimization (TSPO). TSPO introduces the First-Occurrence Latent Reward (FOLR) mechanism, allocating partial rewards to the step where the ground-truth answer first appears, thereby preserving process-level signals and increasing reward variance within groups without requiring external reward models or any annotations. Extensive experiments demonstrate that TSPO significantly outperforms state-of-the-art baselines, achieving average performance gains of 24% and 13.6% on Qwen2.5-3B and 7B models, respectively.
Mirror-Consistency: Harnessing Inconsistency in Majority Voting
Oct 07, 2024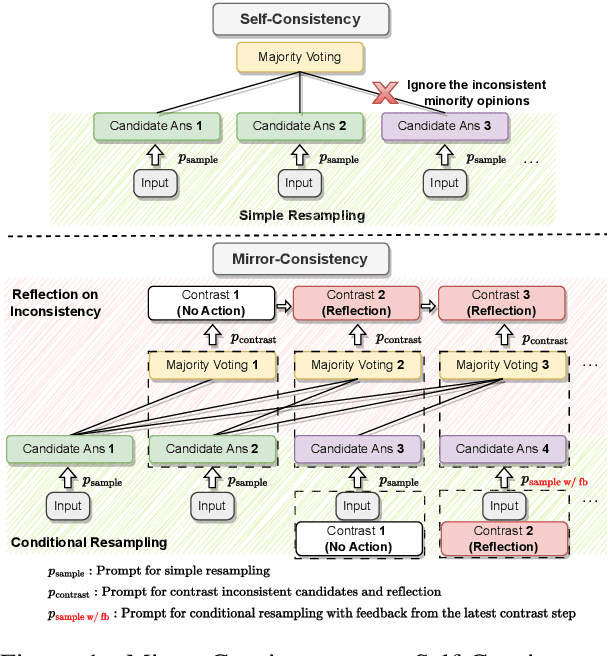
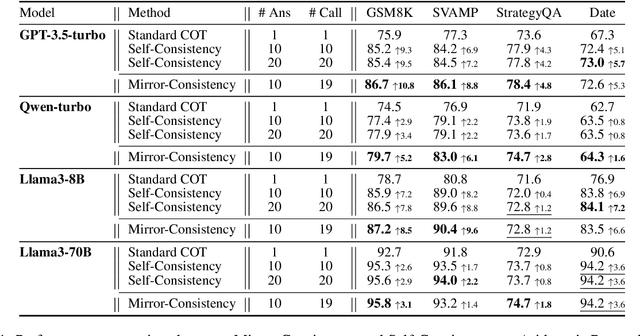
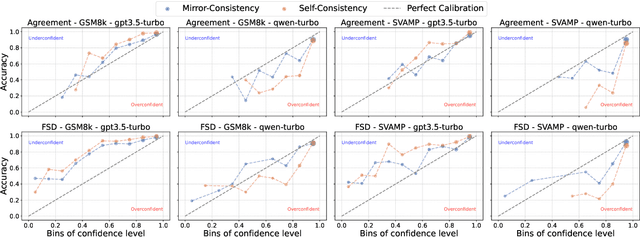
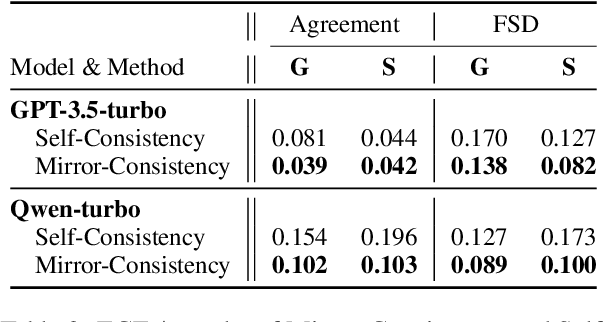
Self-Consistency, a widely-used decoding strategy, significantly boosts the reasoning capabilities of Large Language Models (LLMs). However, it depends on the plurality voting rule, which focuses on the most frequent answer while overlooking all other minority responses. These inconsistent minority views often illuminate areas of uncertainty within the model's generation process. To address this limitation, we present Mirror-Consistency, an enhancement of the standard Self-Consistency approach. Our method incorporates a 'reflective mirror' into the self-ensemble decoding process and enables LLMs to critically examine inconsistencies among multiple generations. Additionally, just as humans use the mirror to better understand themselves, we propose using Mirror-Consistency to enhance the sample-based confidence calibration methods, which helps to mitigate issues of overconfidence. Our experimental results demonstrate that Mirror-Consistency yields superior performance in both reasoning accuracy and confidence calibration compared to Self-Consistency.