 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Guided Data-Efficient Training for Multimodal Reasoning Reward Models
Feb 02, 2026Multimodal reward models are crucial for aligning multimodal large language models with human preferences. Recent works have incorporated reasoning capabilities into these models, achieving promising results. However, training these models suffers from two critical challenges: (1) the inherent noise in preference datasets, which degrades model performance, and (2) the inefficiency of conventional training methods, which ignore the differences in sample difficulty. In this paper, we identify a strong correlation between response entropy and accuracy, indicating that entropy can serve as a reliable and unsupervised proxy for annotation noise and sample difficulty. Based on this insight, we propose a novel Entropy-Guided Training (EGT) approach for multimodal reasoning reward models, which combines two strategies: (1) entropy-guided data curation to mitigate the impact of unreliable samples, and (2) an entropy-guided training strategy that progressively introduces more complex examples. Extensive experiments across three benchmarks show that the EGT-trained model consistently outperforms state-of-the-art multimodal reward models.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Differentiable Collision-Supervised Tooth Arrangement Network with a Decoupling Perspective
Sep 18, 2024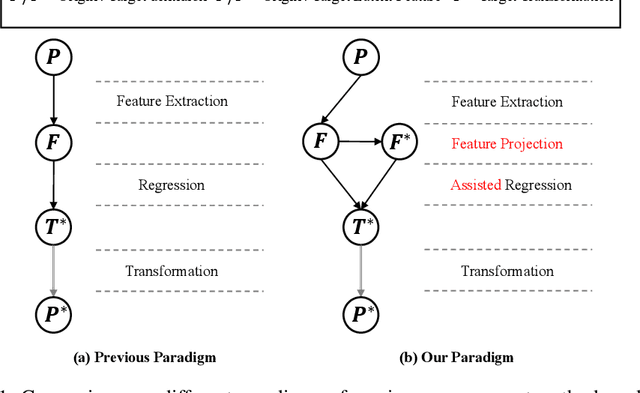

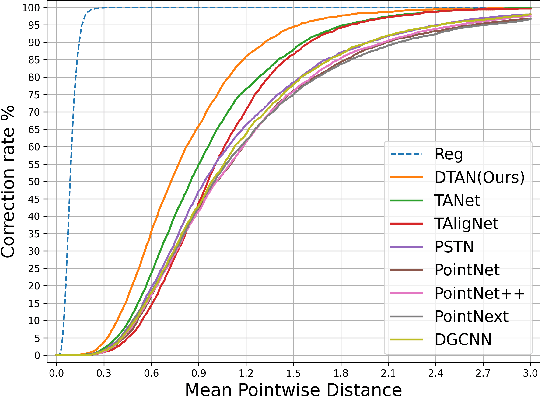

Tooth arrangement is an essential step in the digital orthodontic planning process. Existing learning-based methods use hidden teeth features to directly regress teeth motions, which couples target pose perception and motion regression. It could lead to poor perceptions of three-dimensional transformation. They also ignore the possible overlaps or gaps between teeth of predicted dentition, which is generally unacceptable. Therefore, we propose DTAN, a differentiable collision-supervised tooth arrangement network, decoupling predicting tasks and feature modeling. DTAN decouples the tooth arrangement task by first predicting the hidden features of the final teeth poses and then using them to assist in regressing the motions between the beginning and target teeth. To learn the hidden features better, DTAN also decouples the teeth-hidden features into geometric and positional features, which are further supervised by feature consistency constraints. Furthermore, we propose a novel differentiable collision loss function for point cloud data to constrain the related gestures between teeth, which can be easily extended to other 3D point cloud tasks. We propose an arch-width guided tooth arrangement network, named C-DTAN, to make the results controllable. We construct three different tooth arrangement datasets and achieve drastically improved performance on accuracy and speed compared with existing methods.