 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeULMA: Unified Language Model Alignment with Demonstration and Point-wise Human Preference
Paper and Code
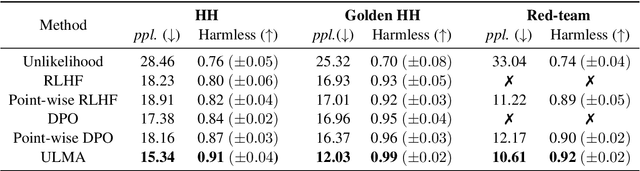
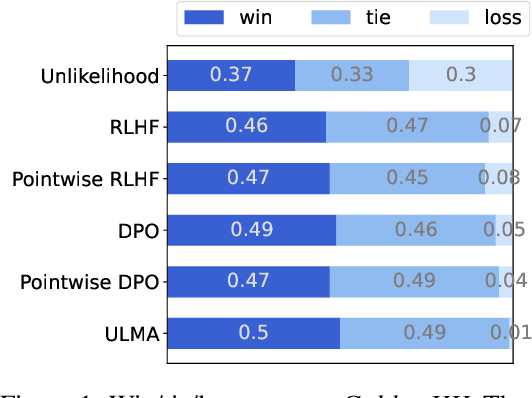
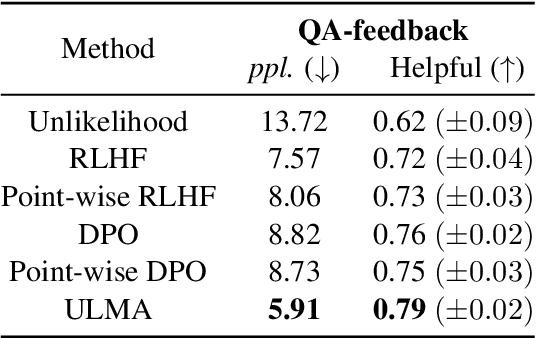
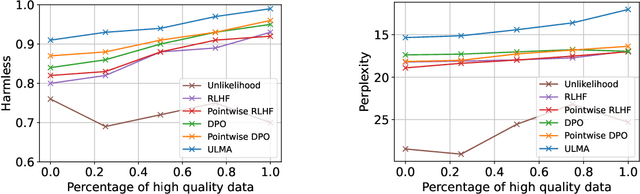
Language model alignment is a cutting-edge technique in large language model training to align the model output to user's intent, e.g., being helpful and harmless. Recent alignment framework consists of two steps: supervised fine-tuning with demonstration data and preference learning with human preference data. Previous preference learning methods, such as RLHF and DPO, mainly focus on pair-wise preference data. However, in many real-world scenarios where human feedbacks are intrinsically point-wise, these methods will suffer from information loss or even fail. To fill this gap, in this paper, we first develop a preference learning method called point-wise DPO to tackle point-wise preference data. Further revelation on the connection between supervised fine-tuning and point-wise preference learning enables us to develop a unified framework for both human demonstration and point-wise preference data, which sheds new light on the construction of preference dataset. Extensive experiments on point-wise datasets with binary or continuous labels demonstrate the superior performance and efficiency of our proposed methods. A new dataset with high-quality demonstration samples on harmlessness is constructed and made publicly available.