 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms and Theory for Supervised Gradual Domain Adaptation
Paper and Code
Apr 25, 2022
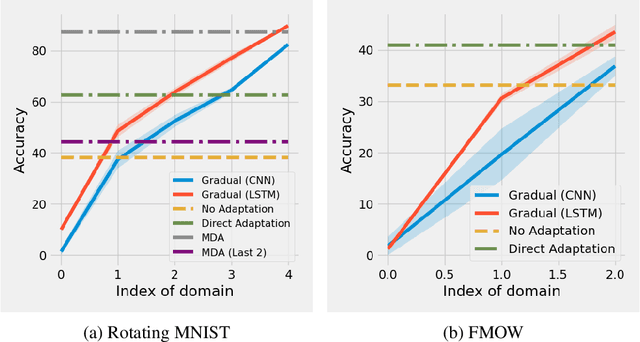
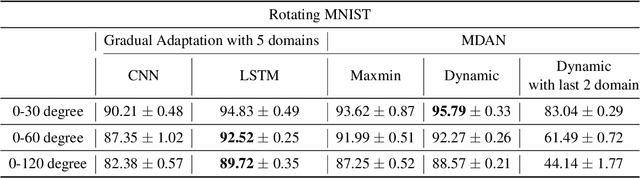

The phenomenon of data distribution evolving over time has been observed in a range of applications, calling the needs of adaptive learning algorithms. We thus study the problem of supervised gradual domain adaptation, where labeled data from shifting distributions are available to the learner along the trajectory, and we aim to learn a classifier on a target data distribution of interest. Under this setting, we provide the first generalization upper bound on the learning error under mild assumptions. Our results are algorithm agnostic, general for a range of loss functions, and only depend linearly on the averaged learning error across the trajectory. This shows significant improvement compared to the previous upper bound for unsupervised gradual domain adaptation, where the learning error on the target domain depends exponentially on the initial error on the source domain. Compared with the offline setting of learning from multiple domains, our results also suggest the potential benefits of the temporal structure among different domains in adapting to the target one. Empirically, our theoretical results imply that learning proper representations across the domains will effectively mitigate the learning errors. Motivated by these theoretical insights, we propose a min-max learning objective to learn the representation and classifier simultaneously. Experimental results on both semi-synthetic and large-scale real datasets corroborate our findings and demonstrate the effectiveness of our objectives.