 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Language Models with Natural Language Feedback
Paper and Code
May 02, 2022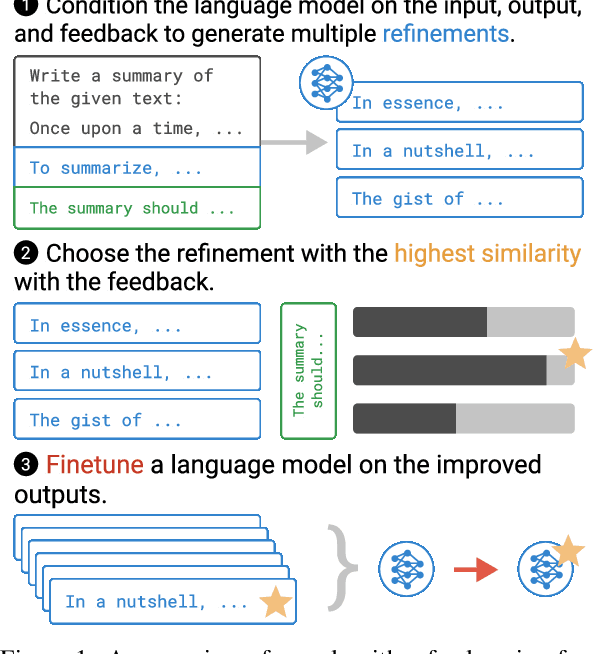
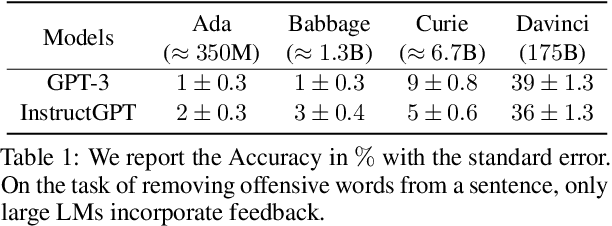
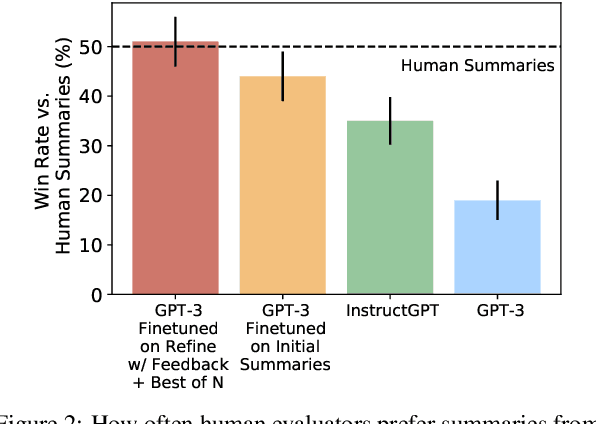
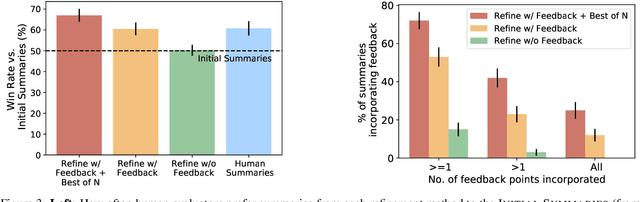
Pretrained language models often do not perform tasks in ways that are in line with our preferences, e.g., generating offensive text or factually incorrect summaries. Recent work approaches the above issue by learning from a simple form of human evaluation: comparisons between pairs of model-generated task outputs. Comparison feedback conveys limited information about human preferences per human evaluation. Here, we propose to learn from natural language feedback, which conveys more information per human evaluation. We learn from language feedback on model outputs using a three-step learning algorithm. First, we condition the language model on the initial output and feedback to generate many refinements. Second, we choose the refinement with the highest similarity to the feedback. Third, we finetune a language model to maximize the likelihood of the chosen refinement given the input. In synthetic experiments, we first evaluate whether language models accurately incorporate feedback to produce refinements, finding that only large language models (175B parameters) do so. Using only 100 samples of human-written feedback, our learning algorithm finetunes a GPT-3 model to roughly human-level summarization.