 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-square-B: Deep Distribution Bound for Natural-looking Adversarial Attack
Paper and Code


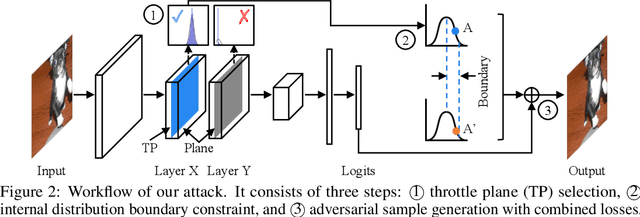
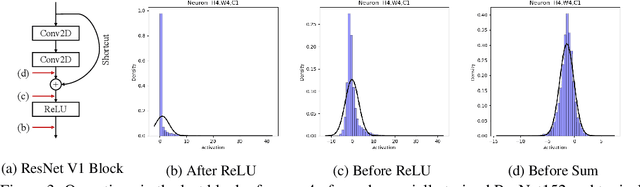
We propose a novel technique that can generate natural-looking adversarial examples by bounding the variations induced for internal activation values in some deep layer(s), through a distribution quantile bound and a polynomial barrier loss function. By bounding model internals instead of individual pixels, our attack admits perturbations closely coupled with the existing features of the original input, allowing the generated examples to be natural-looking while having diverse and often substantial pixel distances from the original input. Enforcing per-neuron distribution quantile bounds allows addressing the non-uniformity of internal activation values. Our evaluation on ImageNet and five different model architecture demonstrates that our attack is quite effective. Compared to the state-of-the-art pixel space attack, semantic attack, and feature space attack, our attack can achieve the same attack success/confidence level while having much more natural-looking adversarial perturbations. These perturbations piggy-back on existing local features and do not have any fixed pixel bounds.