Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Feature Space Adversarial Attack
Paper and Code


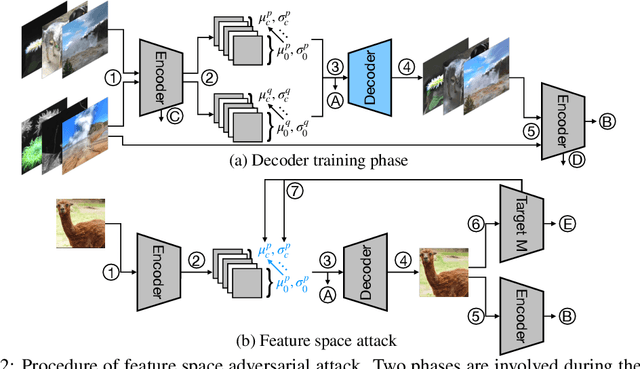
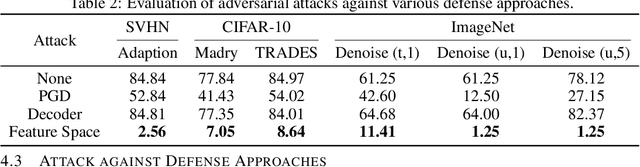
We propose a new type of adversarial attack to Deep Neural Networks (DNNs) for image classification. Different from most existing attacks that directly perturb input pixels. Our attack focuses on perturbing abstract features, more specifically, features that denote styles, including interpretable styles such as vivid colors and sharp outlines, and uninterpretable ones. It induces model misclassfication by injecting style changes insensitive for humans, through an optimization procedure. We show that state-of-the-art adversarial attack detection and defense techniques are ineffective in guarding against feature space attacks.
View paper on
 OpenReview
OpenReview