 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM^3Builder: A Multi-Agent System for Automated Machine Learning in Medical Imaging
Feb 27, 2025Agentic AI systems have gained significant attention for their ability to autonomously perform complex tasks. However, their reliance on well-prepared tools limits their applicability in the medical domain, which requires to train specialized models. In this paper, we make three contributions: (i) We present M3Builder, a novel multi-agent system designed to automate machine learning (ML) in medical imaging. At its core, M3Builder employs four specialized agents that collaborate to tackle complex, multi-step medical ML workflows, from automated data processing and environment configuration to self-contained auto debugging and model training. These agents operate within a medical imaging ML workspace, a structured environment designed to provide agents with free-text descriptions of datasets, training codes, and interaction tools, enabling seamless communication and task execution. (ii) To evaluate progress in automated medical imaging ML, we propose M3Bench, a benchmark comprising four general tasks on 14 training datasets, across five anatomies and three imaging modalities, covering both 2D and 3D data. (iii) We experiment with seven state-of-the-art large language models serving as agent cores for our system, such as Claude series, GPT-4o, and DeepSeek-V3. Compared to existing ML agentic designs, M3Builder shows superior performance on completing ML tasks in medical imaging, achieving a 94.29% success rate using Claude-3.7-Sonnet as the agent core, showing huge potential towards fully automated machine learning in medical imaging.
Can Modern LLMs Act as Agent Cores in Radiology~Environments?
Dec 12, 2024

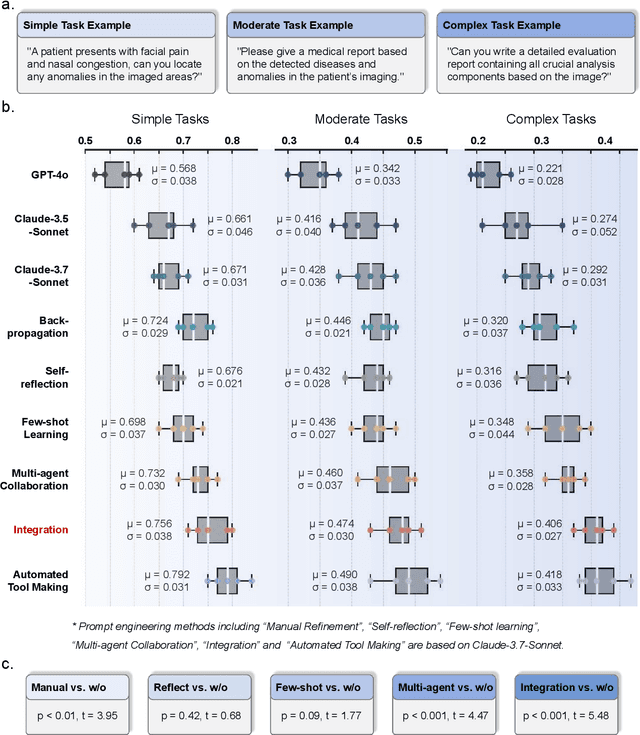

Advancements in large language models (LLMs) have paved the way for LLM-based agent systems that offer enhanced accuracy and interpretability across various domains. Radiology, with its complex analytical requirements, is an ideal field for the application of these agents. This paper aims to investigate the pre-requisite question for building concrete radiology agents which is, `Can modern LLMs act as agent cores in radiology environments?' To investigate it, we introduce RadABench with three-fold contributions: First, we present RadABench-Data, a comprehensive synthetic evaluation dataset for LLM-based agents, generated from an extensive taxonomy encompassing 6 anatomies, 5 imaging modalities, 10 tool categories, and 11 radiology tasks. Second, we propose RadABench-EvalPlat, a novel evaluation platform for agents featuring a prompt-driven workflow and the capability to simulate a wide range of radiology toolsets. Third, we assess the performance of 7 leading LLMs on our benchmark from 5 perspectives with multiple metrics. Our findings indicate that while current LLMs demonstrate strong capabilities in many areas, they are still not sufficiently advanced to serve as the central agent core in a fully operational radiology agent system. Additionally, we identify key factors influencing the performance of LLM-based agent cores, offering insights for clinicians on how to apply agent systems in real-world radiology practices effectively. All of our code and data are open-sourced in https://github.com/MAGIC-AI4Med/RadABench.
Large-scale Long-tailed Disease Diagnosis on Radiology Images
Dec 28, 2023In this study, we aim to investigate the problem of large-scale, large-vocabulary disease classification for radiologic images, which can be formulated as a multi-modal, multi-anatomy, multi-label, long-tailed classification. Our main contributions are three folds: (i), on dataset construction, we build up an academically accessible, large-scale diagnostic dataset that encompasses 5568 disorders linked with 930 unique ICD-10-CM codes, containing 39,026 cases (192,675 scans). (ii), on model design, we present a novel architecture that enables to process arbitrary number of input scans, from various imaging modalities, which is trained with knowledge enhancement to leverage the rich domain knowledge; (iii), on evaluation, we initialize a new benchmark for multi-modal multi-anatomy long-tailed diagnosis. Our method shows superior results on it. Additionally, our final model serves as a pre-trained model, and can be finetuned to benefit diagnosis on various external datasets.
Can GPT-4V Serve Medical Applications? Case Studies on GPT-4V for Multimodal Medical Diagnosis
Oct 17, 2023Driven by the large foundation models, the development of artificial intelligence has witnessed tremendous progress lately, leading to a surge of general interest from the public. In this study, we aim to assess the performance of OpenAI's newest model, GPT-4V(ision), specifically in the realm of multimodal medical diagnosis. Our evaluation encompasses 17 human body systems, including Central Nervous System, Head and Neck, Cardiac, Chest, Hematology, Hepatobiliary, Gastrointestinal, Urogenital, Gynecology, Obstetrics, Breast, Musculoskeletal, Spine, Vascular, Oncology, Trauma, Pediatrics, with images taken from 8 modalities used in daily clinic routine, e.g., X-ray, Computed Tomography (CT), Magnetic Resonance Imaging (MRI), Positron Emission Tomography (PET), Digital Subtraction Angiography (DSA), Mammography, Ultrasound, and Pathology. We probe the GPT-4V's ability on multiple clinical tasks with or without patent history provided, including imaging modality and anatomy recognition, disease diagnosis, report generation, disease localisation. Our observation shows that, while GPT-4V demonstrates proficiency in distinguishing between medical image modalities and anatomy, it faces significant challenges in disease diagnosis and generating comprehensive reports. These findings underscore that while large multimodal models have made significant advancements in computer vision and natural language processing, it remains far from being used to effectively support real-world medical applications and clinical decision-making. All images used in this report can be found in https://github.com/chaoyi-wu/GPT-4V_Medical_Evaluation.