 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-THEBench: Do Reasoning MLLMs Think Reasonably?
Jan 30, 2026Recent advances in multimodal large language models (MLLMs) mark a shift from non-thinking models to post-trained reasoning models capable of solving complex problems through thinking. However, whether such thinking mitigates hallucinations in multimodal perception and reasoning remains unclear. Self-reflective reasoning enhances robustness but introduces additional hallucinations, and subtle perceptual errors still result in incorrect or coincidentally correct answers. Existing benchmarks primarily focus on models before the emergence of reasoning MLLMs, neglecting the internal thinking process and failing to measure the hallucinations that occur during thinking. To address these challenges, we introduce MM-THEBench, a comprehensive benchmark for assessing hallucinations of intermediate CoTs in reasoning MLLMs. MM-THEBench features a fine-grained taxonomy grounded in cognitive dimensions, diverse data with verified reasoning annotations, and a multi-level automated evaluation framework. Extensive experiments on mainstream reasoning MLLMs reveal insights into how thinking affects hallucination and reasoning capability in various multimodal tasks.
How does Transformer Learn Implicit Reasoning?
May 29, 2025

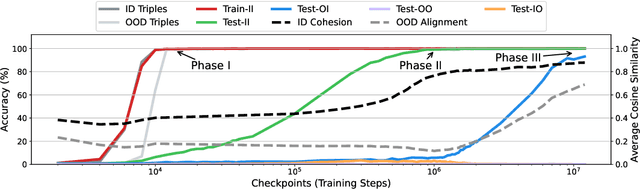

Recent work suggests that large language models (LLMs) can perform multi-hop reasoning implicitly -- producing correct answers without explicitly verbalizing intermediate steps -- but the underlying mechanisms remain poorly understood. In this paper, we study how such implicit reasoning emerges by training transformers from scratch in a controlled symbolic environment. Our analysis reveals a three-stage developmental trajectory: early memorization, followed by in-distribution generalization, and eventually cross-distribution generalization. We find that training with atomic triples is not necessary but accelerates learning, and that second-hop generalization relies on query-level exposure to specific compositional structures. To interpret these behaviors, we introduce two diagnostic tools: cross-query semantic patching, which identifies semantically reusable intermediate representations, and a cosine-based representational lens, which reveals that successful reasoning correlates with the cosine-base clustering in hidden space. This clustering phenomenon in turn provides a coherent explanation for the behavioral dynamics observed across training, linking representational structure to reasoning capability. These findings provide new insights into the interpretability of implicit multi-hop reasoning in LLMs, helping to clarify how complex reasoning processes unfold internally and offering pathways to enhance the transparency of such models.
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Aug 28, 2023Although large language models (LLMs) demonstrate impressive performance for many language tasks, most of them can only handle texts a few thousand tokens long, limiting their applications on longer sequence inputs, such as books, reports, and codebases. Recent works have proposed methods to improve LLMs' long context capabilities by extending context windows and more sophisticated memory mechanisms. However, comprehensive benchmarks tailored for evaluating long context understanding are lacking. In this paper, we introduce LongBench, the first bilingual, multi-task benchmark for long context understanding, enabling a more rigorous evaluation of long context understanding. LongBench comprises 21 datasets across 6 task categories in both English and Chinese, with an average length of 6,711 words (English) and 13,386 characters (Chinese). These tasks cover key long-text application areas including single-doc QA, multi-doc QA, summarization, few-shot learning, synthetic tasks, and code completion. All datasets in LongBench are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Upon comprehensive evaluation of 8 LLMs on LongBench, we find that: (1) Commercial model (GPT-3.5-Turbo-16k) outperforms other open-sourced models, but still struggles on longer contexts. (2) Scaled position embedding and fine-tuning on longer sequences lead to substantial improvement on long context understanding. (3) Context compression technique such as retrieval brings improvement for model with weak ability on long contexts, but the performance still lags behind models that have strong long context understanding capability. The code and datasets are available at https://github.com/THUDM/LongBench.