 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Proximal Policy Optimization with Upper Confidence Bound
Paper and Code
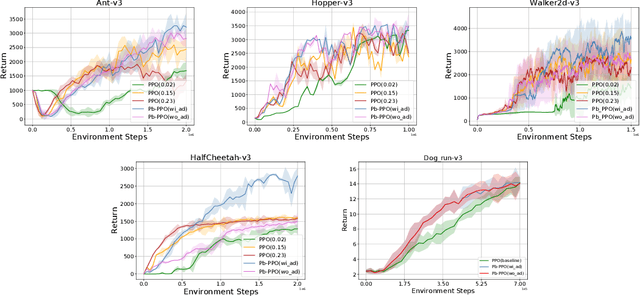

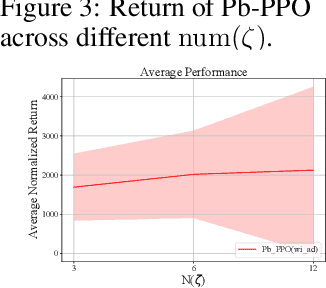

Trust Region Policy Optimization (TRPO) attractively optimizes the policy while constraining the update of the new policy within a trust region, ensuring the stability and monotonic optimization. Building on the theoretical guarantees of trust region optimization, Proximal Policy Optimization (PPO) successfully enhances the algorithm's sample efficiency and reduces deployment complexity by confining the update of the new and old policies within a surrogate trust region. However, this approach is limited by the fixed setting of surrogate trust region and is not sufficiently adaptive, because there is no theoretical proof that the optimal clipping bound remains consistent throughout the entire training process, truncating the ratio of the new and old policies within surrogate trust region can ensure that the algorithm achieves its best performance, therefore, exploring and researching a dynamic clip bound for improving PPO's performance can be quite beneficial. To design an adaptive clipped trust region and explore the dynamic clip bound's impact on the performance of PPO, we introduce an adaptive PPO-CLIP (Adaptive-PPO) method that dynamically explores and exploits the clip bound using a bandit during the online training process. Furthermore, ample experiments will initially demonstrate that our Adaptive-PPO exhibits sample efficiency and performance compared to PPO-CLIP.