 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADR-BC: Adversarial Density Weighted Regression Behavior Cloning
Paper and Code
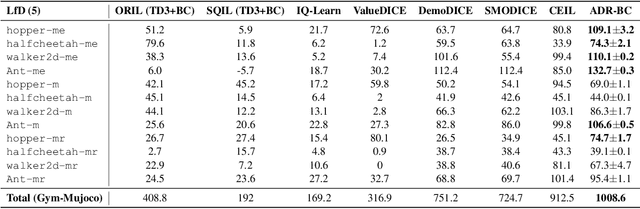
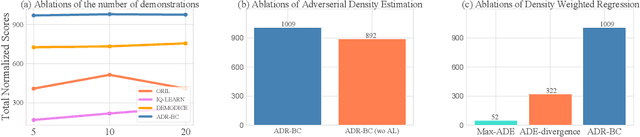
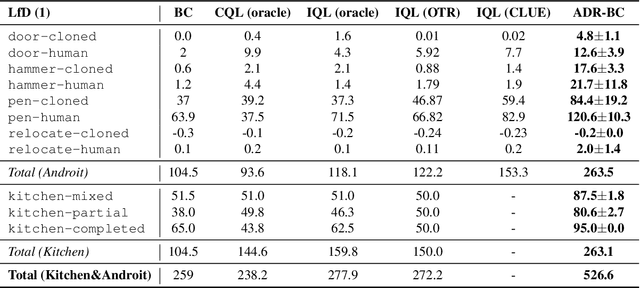
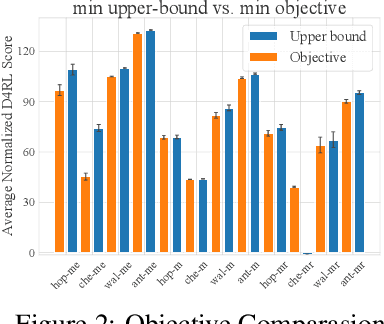
Typically, traditional Imitation Learning (IL) methods first shape a reward or Q function and then use this shaped function within a reinforcement learning (RL) framework to optimize the empirical policy. However, if the shaped reward/Q function does not adequately represent the ground truth reward/Q function, updating the policy within a multi-step RL framework may result in cumulative bias, further impacting policy learning. Although utilizing behavior cloning (BC) to learn a policy by directly mimicking a few demonstrations in a single-step updating manner can avoid cumulative bias, BC tends to greedily imitate demonstrated actions, limiting its capacity to generalize to unseen state action pairs. To address these challenges, we propose ADR-BC, which aims to enhance behavior cloning through augmented density-based action support, optimizing the policy with this augmented support. Specifically, the objective of ADR-BC shares the similar physical meanings that matching expert distribution while diverging the sub-optimal distribution. Therefore, ADR-BC can achieve more robust expert distribution matching. Meanwhile, as a one-step behavior cloning framework, ADR-BC avoids the cumulative bias associated with multi-step RL frameworks. To validate the performance of ADR-BC, we conduct extensive experiments. Specifically, ADR-BC showcases a 10.5% improvement over the previous state-of-the-art (SOTA) generalized IL baseline, CEIL, across all tasks in the Gym-Mujoco domain. Additionally, it achieves an 89.5% improvement over Implicit Q Learning (IQL) using real rewards across all tasks in the Adroit and Kitchen domains. On the other hand, we conduct extensive ablations to further demonstrate the effectiveness of ADR-BC.