 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs FISHER All You Need in The Multi-AUV Underwater Target Tracking Task?
Dec 05, 2024



It is significant to employ multiple autonomous underwater vehicles (AUVs) to execute the underwater target tracking task collaboratively. However, it's pretty challenging to meet various prerequisites utilizing traditional control methods. Therefore, we propose an effective two-stage learning from demonstrations training framework, FISHER, to highlight the adaptability of reinforcement learning (RL) methods in the multi-AUV underwater target tracking task, while addressing its limitations such as extensive requirements for environmental interactions and the challenges in designing reward functions. The first stage utilizes imitation learning (IL) to realize policy improvement and generate offline datasets. To be specific, we introduce multi-agent discriminator-actor-critic based on improvements of the generative adversarial IL algorithm and multi-agent IL optimization objective derived from the Nash equilibrium condition. Then in the second stage, we develop multi-agent independent generalized decision transformer, which analyzes the latent representation to match the future states of high-quality samples rather than reward function, attaining further enhanced policies capable of handling various scenarios. Besides, we propose a simulation to simulation demonstration generation procedure to facilitate the generation of expert demonstrations in underwater environments, which capitalizes on traditional control methods and can easily accomplish the domain transfer to obtain demonstrations. Extensive simulation experiments from multiple scenarios showcase that FISHER possesses strong stability, multi-task performance and capability of generalization.
Cross-modal Image Retrieval with Deep Mutual Information Maximization
Mar 10, 2021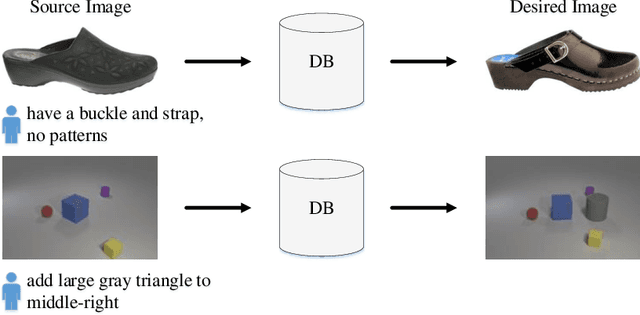
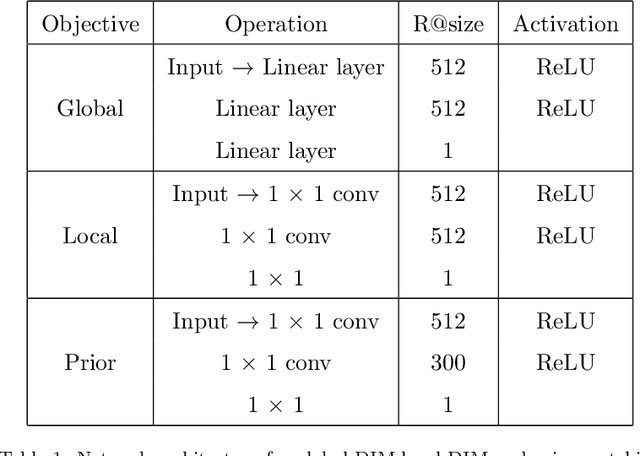
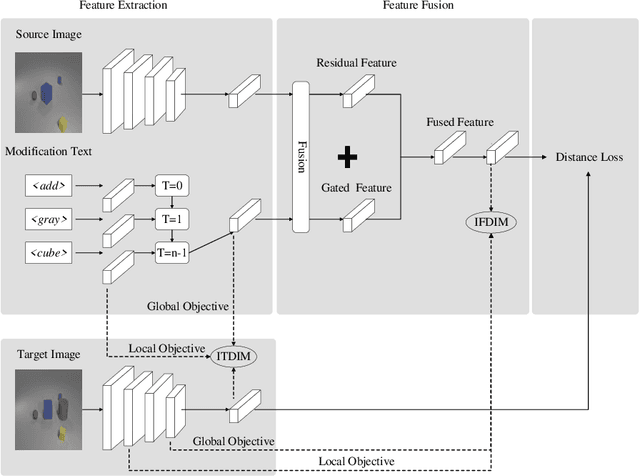
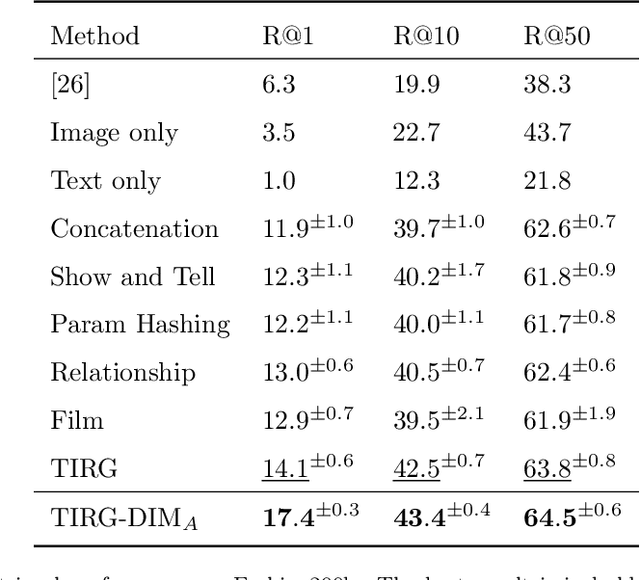
In this paper, we study the cross-modal image retrieval, where the inputs contain a source image plus some text that describes certain modifications to this image and the desired image. Prior work usually uses a three-stage strategy to tackle this task: 1) extract the features of the inputs; 2) fuse the feature of the source image and its modified text to obtain fusion feature; 3) learn a similarity metric between the desired image and the source image + modified text by using deep metric learning. Since classical image/text encoders can learn the useful representation and common pair-based loss functions of distance metric learning are enough for cross-modal retrieval, people usually improve retrieval accuracy by designing new fusion networks. However, these methods do not successfully handle the modality gap caused by the inconsistent distribution and representation of the features of different modalities, which greatly influences the feature fusion and similarity learning. To alleviate this problem, we adopt the contrastive self-supervised learning method Deep InforMax (DIM) to our approach to bridge this gap by enhancing the dependence between the text, the image, and their fusion. Specifically, our method narrows the modality gap between the text modality and the image modality by maximizing mutual information between their not exactly semantically identical representation. Moreover, we seek an effective common subspace for the semantically same fusion feature and desired image's feature by utilizing Deep InforMax between the low-level layer of the image encoder and the high-level layer of the fusion network. Extensive experiments on three large-scale benchmark datasets show that we have bridged the modality gap between different modalities and achieve state-of-the-art retrieval performance.