 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Image Retrieval with Deep Mutual Information Maximization
Mar 10, 2021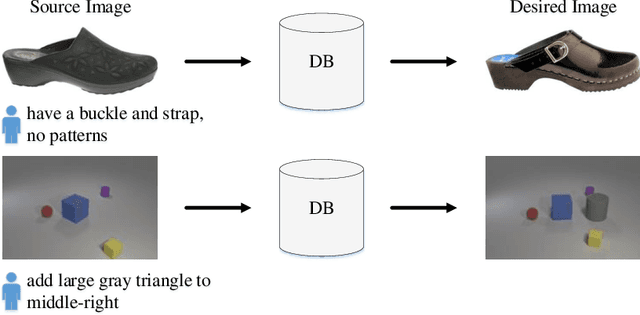
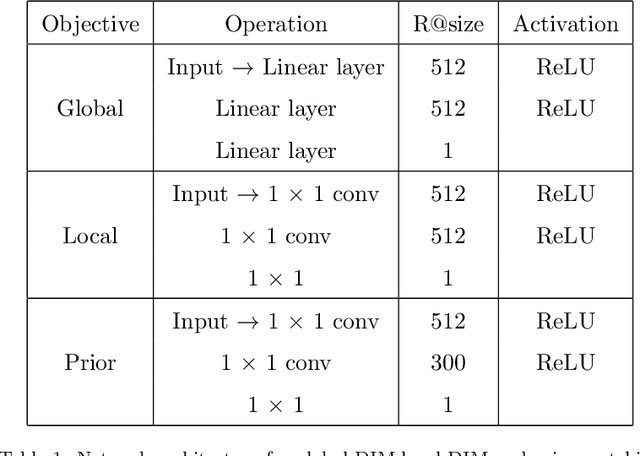
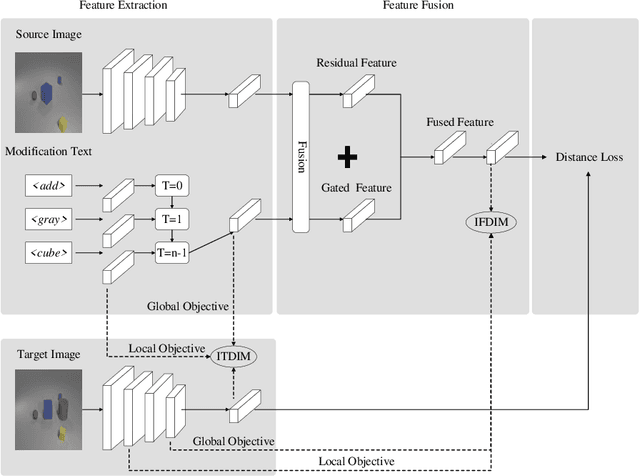
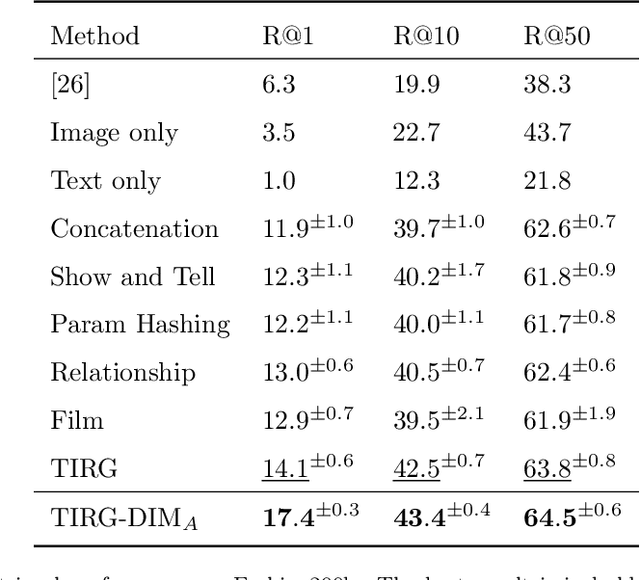
In this paper, we study the cross-modal image retrieval, where the inputs contain a source image plus some text that describes certain modifications to this image and the desired image. Prior work usually uses a three-stage strategy to tackle this task: 1) extract the features of the inputs; 2) fuse the feature of the source image and its modified text to obtain fusion feature; 3) learn a similarity metric between the desired image and the source image + modified text by using deep metric learning. Since classical image/text encoders can learn the useful representation and common pair-based loss functions of distance metric learning are enough for cross-modal retrieval, people usually improve retrieval accuracy by designing new fusion networks. However, these methods do not successfully handle the modality gap caused by the inconsistent distribution and representation of the features of different modalities, which greatly influences the feature fusion and similarity learning. To alleviate this problem, we adopt the contrastive self-supervised learning method Deep InforMax (DIM) to our approach to bridge this gap by enhancing the dependence between the text, the image, and their fusion. Specifically, our method narrows the modality gap between the text modality and the image modality by maximizing mutual information between their not exactly semantically identical representation. Moreover, we seek an effective common subspace for the semantically same fusion feature and desired image's feature by utilizing Deep InforMax between the low-level layer of the image encoder and the high-level layer of the fusion network. Extensive experiments on three large-scale benchmark datasets show that we have bridged the modality gap between different modalities and achieve state-of-the-art retrieval performance.
Few-Shot Graph Classification with Model Agnostic Meta-Learning
Mar 18, 2020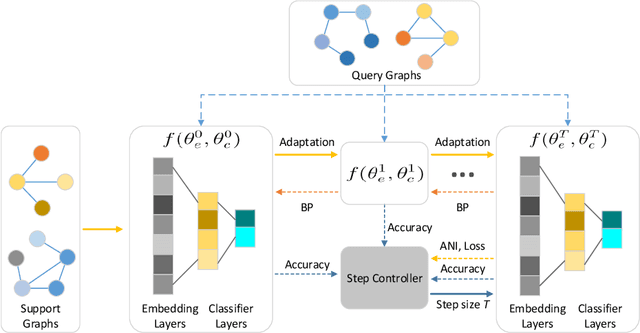
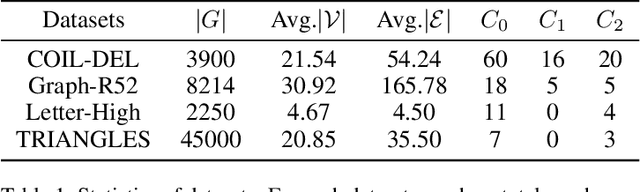
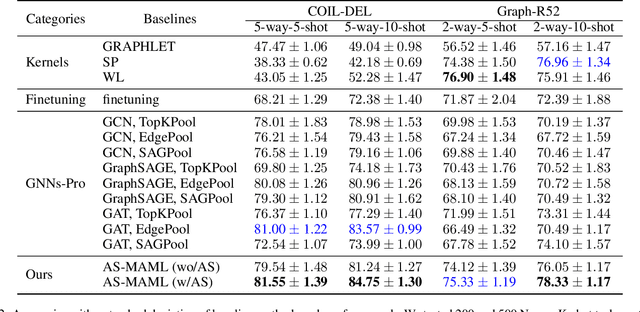
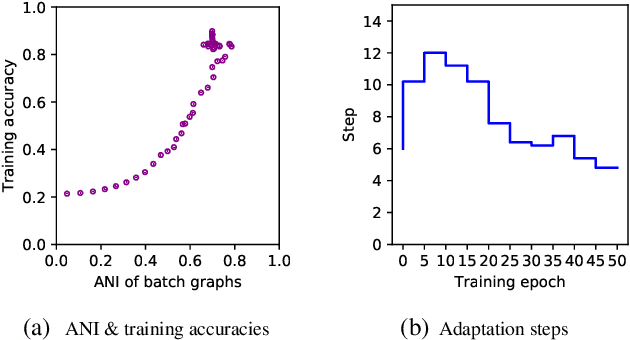
Graph classification aims to perform accurate information extraction and classification over graphstructured data. In the past few years, Graph Neural Networks (GNNs) have achieved satisfactory performance on graph classification tasks. However, most GNNs based methods focus on designing graph convolutional operations and graph pooling operations, overlooking that collecting or labeling graph-structured data is more difficult than grid-based data. We utilize meta-learning for fewshot graph classification to alleviate the scarce of labeled graph samples when training new tasks.More specifically, to boost the learning of graph classification tasks, we leverage GNNs as graph embedding backbone and meta-learning as training paradigm to capture task-specific knowledge rapidly in graph classification tasks and transfer them to new tasks. To enhance the robustness of meta-learner, we designed a novel step controller driven by Reinforcement Learning. The experiments demonstrate that our framework works well compared to baselines.
Matching Text with Deep Mutual Information Estimation
Mar 09, 2020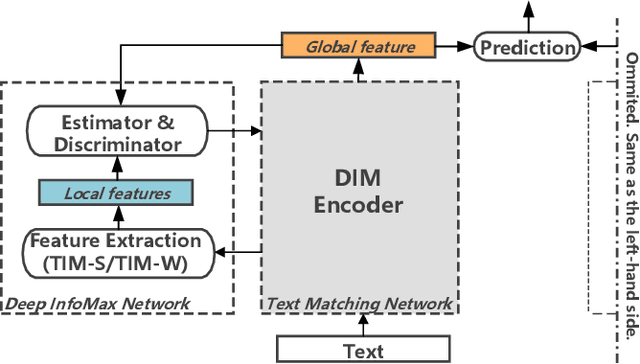
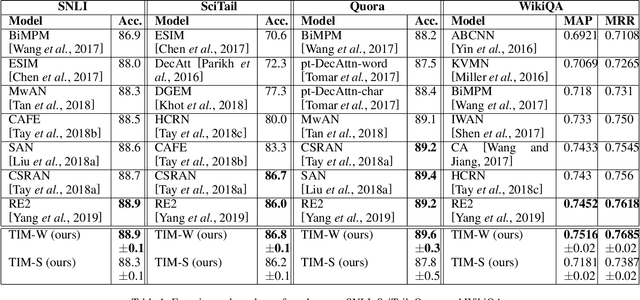
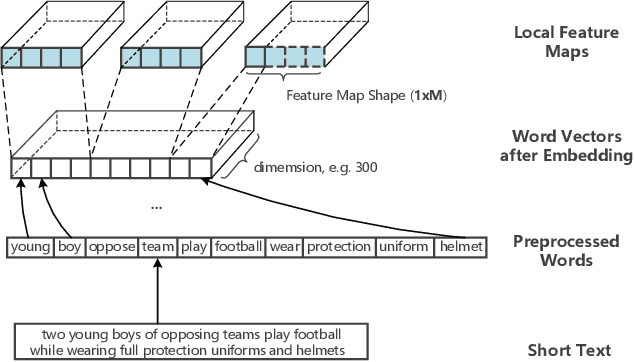
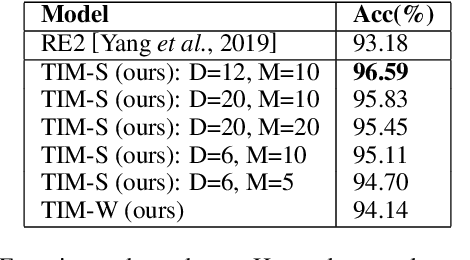
Text matching is a core natural language processing research problem. How to retain sufficient information on both content and structure information is one important challenge. In this paper, we present a neural approach for general-purpose text matching with deep mutual information estimation incorporated. Our approach, Text matching with Deep Info Max (TIM), is integrated with a procedure of unsupervised learning of representations by maximizing the mutual information between text matching neural network's input and output. We use both global and local mutual information to learn text representations. We evaluate our text matching approach on several tasks including natural language inference, paraphrase identification, and answer selection. Compared to the state-of-the-art approaches, the experiments show that our method integrated with mutual information estimation learns better text representation and achieves better experimental results of text matching tasks without exploiting pretraining on external data.
Hierarchical Graph Pooling with Structure Learning
Dec 25, 2019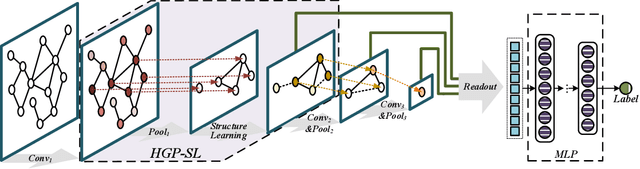
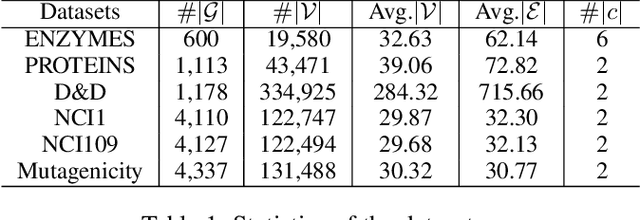

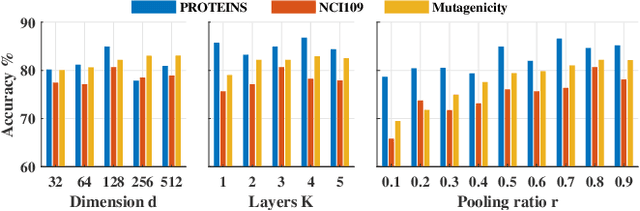
Graph Neural Networks (GNNs), which generalize deep neural networks to graph-structured data, have drawn considerable attention and achieved state-of-the-art performance in numerous graph related tasks. However, existing GNN models mainly focus on designing graph convolution operations. The graph pooling (or downsampling) operations, that play an important role in learning hierarchical representations, are usually overlooked. In this paper, we propose a novel graph pooling operator, called Hierarchical Graph Pooling with Structure Learning (HGP-SL), which can be integrated into various graph neural network architectures. HGP-SL incorporates graph pooling and structure learning into a unified module to generate hierarchical representations of graphs. More specifically, the graph pooling operation adaptively selects a subset of nodes to form an induced subgraph for the subsequent layers. To preserve the integrity of graph's topological information, we further introduce a structure learning mechanism to learn a refined graph structure for the pooled graph at each layer. By combining HGP-SL operator with graph neural networks, we perform graph level representation learning with focus on graph classification task. Experimental results on six widely used benchmarks demonstrate the effectiveness of our proposed model.