 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross- and Intra-image Prototypical Learning for Multi-label Disease Diagnosis and Interpretation
Nov 07, 2024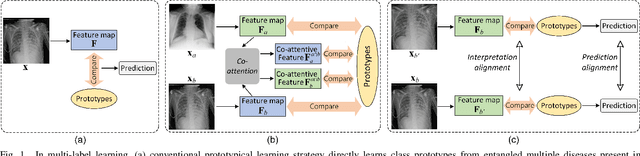
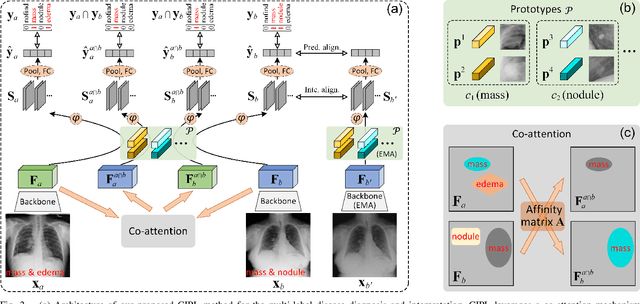
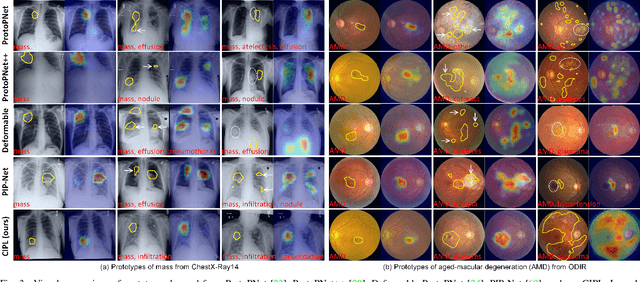
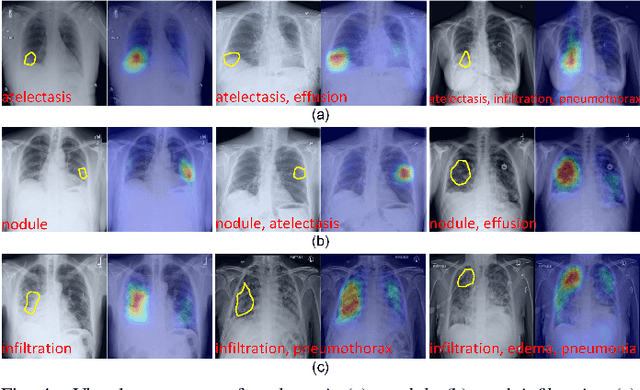
Recent advances in prototypical learning have shown remarkable potential to provide useful decision interpretations associating activation maps and predictions with class-specific training prototypes. Such prototypical learning has been well-studied for various single-label diseases, but for quite relevant and more challenging multi-label diagnosis, where multiple diseases are often concurrent within an image, existing prototypical learning models struggle to obtain meaningful activation maps and effective class prototypes due to the entanglement of the multiple diseases. In this paper, we present a novel Cross- and Intra-image Prototypical Learning (CIPL) framework, for accurate multi-label disease diagnosis and interpretation from medical images. CIPL takes advantage of common cross-image semantics to disentangle the multiple diseases when learning the prototypes, allowing a comprehensive understanding of complicated pathological lesions. Furthermore, we propose a new two-level alignment-based regularisation strategy that effectively leverages consistent intra-image information to enhance interpretation robustness and predictive performance. Extensive experiments show that our CIPL attains the state-of-the-art (SOTA) classification accuracy in two public multi-label benchmarks of disease diagnosis: thoracic radiography and fundus images. Quantitative interpretability results show that CIPL also has superiority in weakly-supervised thoracic disease localisation over other leading saliency- and prototype-based explanation methods.
Mixture of Gaussian-distributed Prototypes with Generative Modelling for Interpretable Image Classification
Nov 30, 2023Prototypical-part interpretable methods, e.g., ProtoPNet, enhance interpretability by connecting classification predictions to class-specific training prototypes, thereby offering an intuitive insight into their decision-making. Current methods rely on a discriminative classifier trained with point-based learning techniques that provide specific values for prototypes. Such prototypes have relatively low representation power due to their sparsity and potential redundancy, with each prototype containing no variability measure. In this paper, we present a new generative learning of prototype distributions, named Mixture of Gaussian-distributed Prototypes (MGProto), which are represented by Gaussian mixture models (GMM). Such an approach enables the learning of more powerful prototype representations since each learned prototype will own a measure of variability, which naturally reduces the sparsity given the spread of the distribution around each prototype, and we also integrate a prototype diversity objective function into the GMM optimisation to reduce redundancy. Incidentally, the generative nature of MGProto offers a new and effective way for detecting out-of-distribution samples. To improve the compactness of MGProto, we further propose to prune Gaussian-distributed prototypes with a low prior. Experiments on CUB-200-2011, Stanford Cars, Stanford Dogs, and Oxford-IIIT Pets datasets show that MGProto achieves state-of-the-art classification and OoD detection performances with encouraging interpretability results.
BRAIxDet: Learning to Detect Malignant Breast Lesion with Incomplete Annotations
Feb 02, 2023



Methods to detect malignant lesions from screening mammograms are usually trained with fully annotated datasets, where images are labelled with the localisation and classification of cancerous lesions. However, real-world screening mammogram datasets commonly have a subset that is fully annotated and another subset that is weakly annotated with just the global classification (i.e., without lesion localisation). Given the large size of such datasets, researchers usually face a dilemma with the weakly annotated subset: to not use it or to fully annotate it. The first option will reduce detection accuracy because it does not use the whole dataset, and the second option is too expensive given that the annotation needs to be done by expert radiologists. In this paper, we propose a middle-ground solution for the dilemma, which is to formulate the training as a weakly- and semi-supervised learning problem that we refer to as malignant breast lesion detection with incomplete annotations. To address this problem, our new method comprises two stages, namely: 1) pre-training a multi-view mammogram classifier with weak supervision from the whole dataset, and 2) extending the trained classifier to become a multi-view detector that is trained with semi-supervised student-teacher learning, where the training set contains fully and weakly-annotated mammograms. We provide extensive detection results on two real-world screening mammogram datasets containing incomplete annotations, and show that our proposed approach achieves state-of-the-art results in the detection of malignant breast lesions with incomplete annotations.
Learning Support and Trivial Prototypes for Interpretable Image Classification
Jan 08, 2023



Prototypical part network (ProtoPNet) methods have been designed to achieve interpretable classification by associating predictions with a set of training prototypes, which we refer to as trivial (i.e., easy-to-learn) prototypes because they are trained to lie far from the classification boundary in the feature space. Note that it is possible to make an analogy between ProtoPNet and support vector machine (SVM) given that the classification from both methods relies on computing similarity with a set of training points (i.e., trivial prototypes in ProtoPNet, and support vectors in SVM). However, while trivial prototypes are located far from the classification boundary, support vectors are located close to this boundary, and we argue that this discrepancy with the well-established SVM theory can result in ProtoPNet models with suboptimal classification accuracy. In this paper, we aim to improve the classification accuracy of ProtoPNet with a new method to learn support prototypes that lie near the classification boundary in the feature space, as suggested by the SVM theory. In addition, we target the improvement of classification interpretability with a new model, named ST-ProtoPNet, which exploits our support prototypes and the trivial prototypes to provide complementary interpretability information. Experimental results on CUB-200-2011, Stanford Cars, and Stanford Dogs datasets demonstrate that the proposed method achieves state-of-the-art classification accuracy and produces more visually meaningful and diverse prototypes.
Knowledge Distillation to Ensemble Global and Interpretable Prototype-Based Mammogram Classification Models
Sep 26, 2022State-of-the-art (SOTA) deep learning mammogram classifiers, trained with weakly-labelled images, often rely on global models that produce predictions with limited interpretability, which is a key barrier to their successful translation into clinical practice. On the other hand, prototype-based models improve interpretability by associating predictions with training image prototypes, but they are less accurate than global models and their prototypes tend to have poor diversity. We address these two issues with the proposal of BRAIxProtoPNet++, which adds interpretability to a global model by ensembling it with a prototype-based model. BRAIxProtoPNet++ distills the knowledge of the global model when training the prototype-based model with the goal of increasing the classification accuracy of the ensemble. Moreover, we propose an approach to increase prototype diversity by guaranteeing that all prototypes are associated with different training images. Experiments on weakly-labelled private and public datasets show that BRAIxProtoPNet++ has higher classification accuracy than SOTA global and prototype-based models. Using lesion localisation to assess model interpretability, we show BRAIxProtoPNet++ is more effective than other prototype-based models and post-hoc explanation of global models. Finally, we show that the diversity of the prototypes learned by BRAIxProtoPNet++ is superior to SOTA prototype-based approaches.
Multi-view Local Co-occurrence and Global Consistency Learning Improve Mammogram Classification Generalisation
Sep 21, 2022When analysing screening mammograms, radiologists can naturally process information across two ipsilateral views of each breast, namely the cranio-caudal (CC) and mediolateral-oblique (MLO) views. These multiple related images provide complementary diagnostic information and can improve the radiologist's classification accuracy. Unfortunately, most existing deep learning systems, trained with globally-labelled images, lack the ability to jointly analyse and integrate global and local information from these multiple views. By ignoring the potentially valuable information present in multiple images of a screening episode, one limits the potential accuracy of these systems. Here, we propose a new multi-view global-local analysis method that mimics the radiologist's reading procedure, based on a global consistency learning and local co-occurrence learning of ipsilateral views in mammograms. Extensive experiments show that our model outperforms competing methods, in terms of classification accuracy and generalisation, on a large-scale private dataset and two publicly available datasets, where models are exclusively trained and tested with global labels.