 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Agnostic Incremental Learning for Sound Classification. A DCASE 2026 Challenge task
Jun 01, 2026This paper presents the Domain-Agnostic Incremental Learning for Audio Classification Task of the DCASE 2026 Challenge. Incremental learning refers to sequentially learning new tasks with the same system while maintaining its knowledge and performance on the previously learned task. Domain-incremental learning for sound classification refers to learning the same sound classes but in different acoustic domains, and was formalized as a data challenge for the first time in DCASE 2026. Participants will train a system to learn ten sound classes in three different domains, with learning at each incremental task not having access to previous task data. Submitted systems will be ranked by the overall average accuracy calculated over the three domains. The provided baseline system obtains a modest performance of 44.9\% accuracy over the three domains, mostly due to erroneous inference of the domain for the test sample.
Online incremental learning for audio classification using a pretrained audio model
Aug 28, 2025



Incremental learning aims to learn new tasks sequentially without forgetting the previously learned ones. Most of the existing incremental learning methods for audio focus on training the model from scratch on the initial task, and the same model is used to learn upcoming incremental tasks. The model is trained for several iterations to adapt to each new task, using some specific approaches to reduce the forgetting of old tasks. In this work, we propose a method for using generalizable audio embeddings produced by a pre-trained model to develop an online incremental learner that solves sequential audio classification tasks over time. Specifically, we inject a layer with a nonlinear activation function between the pre-trained model's audio embeddings and the classifier; this layer expands the dimensionality of the embeddings and effectively captures the distinct characteristics of sound classes. Our method adapts the model in a single forward pass (online) through the training samples of any task, with minimal forgetting of old tasks. We demonstrate the performance of the proposed method in two incremental learning setups: one class-incremental learning using ESC-50 and one domain-incremental learning of different cities from the TAU Urban Acoustic Scenes 2019 dataset; for both cases, the proposed approach outperforms other methods.
Domain-Incremental Learning for Audio Classification
Dec 23, 2024In this work, we propose a method for domain-incremental learning for audio classification from a sequence of datasets recorded in different acoustic conditions. Fine-tuning a model on a sequence of evolving domains or datasets leads to forgetting of previously learned knowledge. On the other hand, freezing all the layers of the model leads to the model not adapting to the new domain. In this work, our novel dynamic network architecture keeps the shared homogeneous acoustic characteristics of domains, and learns the domain-specific acoustic characteristics in incremental steps. Our approach achieves a good balance between retaining the knowledge of previously learned domains and acquiring the knowledge of the new domain. We demonstrate the effectiveness of the proposed method on incremental learning of single-label classification of acoustic scenes from European cities and Korea, and multi-label classification of audio recordings from Audioset and FSD50K datasets. The proposed approach learns to classify acoustic scenes incrementally with an average accuracy of 71.9% for the order: European cities -> Korea, and 83.4% for Korea -> European cities. In a multi-label audio classification setup, it achieves an average lwlrap of 47.5% for Audioset -> FSD50K and 40.7% for FSD50K -> Audioset.
Class-Incremental Learning for Sound Event Localization and Detection
Nov 19, 2024This paper investigates the feasibility of class-incremental learning (CIL) for Sound Event Localization and Detection (SELD) tasks. The method features an incremental learner that can learn new sound classes independently while preserving knowledge of old classes. The continual learning is achieved through a mean square error-based distillation loss to minimize output discrepancies between subsequent learners. The experiments are conducted on the TAU-NIGENS Spatial Sound Events 2021 dataset, which includes 12 different sound classes and demonstrate the efficacy of proposed method. We begin by learning 8 classes and introduce the 4 new classes at next stage. After the incremental phase, the system is evaluated on the full set of learned classes. Results show that, for this realistic dataset, our proposed method successfully maintains baseline performance across all metrics.
Online Domain-Incremental Learning Approach to Classify Acoustic Scenes in All Locations
Jun 19, 2024



In this paper, we propose a method for online domain-incremental learning of acoustic scene classification from a sequence of different locations. Simply training a deep learning model on a sequence of different locations leads to forgetting of previously learned knowledge. In this work, we only correct the statistics of the Batch Normalization layers of a model using a few samples to learn the acoustic scenes from a new location without any excessive training. Experiments are performed on acoustic scenes from 11 different locations, with an initial task containing acoustic scenes from 6 locations and the remaining 5 incremental tasks each representing the acoustic scenes from a different location. The proposed approach outperforms fine-tuning based methods and achieves an average accuracy of 48.8% after learning the last task in sequence without forgetting acoustic scenes from the previously learned locations.
Class-Incremental Learning for Multi-Label Audio Classification
Jan 09, 2024



In this paper, we propose a method for class-incremental learning of potentially overlapping sounds for solving a sequence of multi-label audio classification tasks. We design an incremental learner that learns new classes independently of the old classes. To preserve knowledge about the old classes, we propose a cosine similarity-based distillation loss that minimizes discrepancy in the feature representations of subsequent learners, and use it along with a Kullback-Leibler divergence-based distillation loss that minimizes discrepancy in their respective outputs. Experiments are performed on a dataset with 50 sound classes, with an initial classification task containing 30 base classes and 4 incremental phases of 5 classes each. After each phase, the system is tested for multi-label classification with the entire set of classes learned so far. The proposed method obtains an average F1-score of 40.9% over the five phases, ranging from 45.2% in phase 0 on 30 classes, to 36.3% in phase 4 on 50 classes. Average performance degradation over incremental phases is only 0.7 percentage points from the initial F1-score of 45.2%.
Incremental Learning of Acoustic Scenes and Sound Events
Feb 28, 2023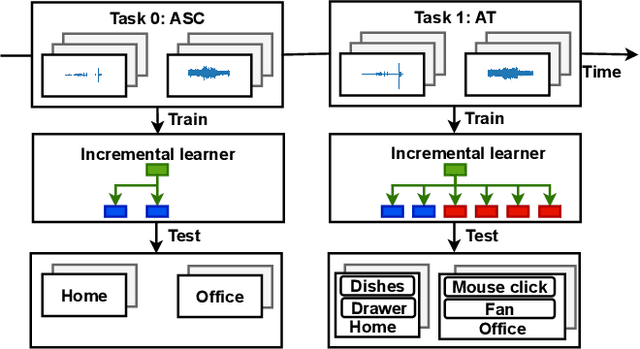
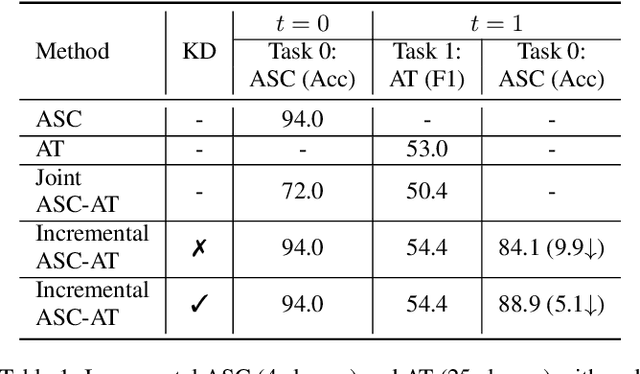
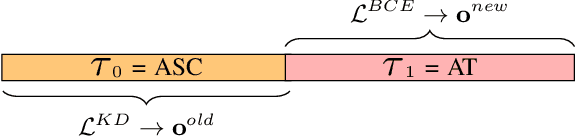
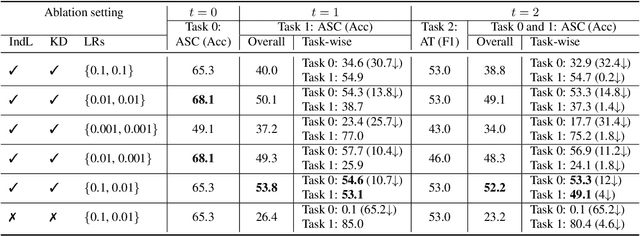
In this paper, we propose a method for incremental learning of two distinct tasks over time: acoustic scene classification (ASC) and audio tagging (AT). We use a simple convolutional neural network (CNN) model as an incremental learner to solve the tasks. Generally, incremental learning methods catastrophically forget the previous task when sequentially trained on a new task. To alleviate this problem, we use independent learning and knowledge distillation (KD) between the timesteps in learning. Experiments are performed on TUT 2016/2017 dataset, containing 4 acoustic scene classes and 25 sound event classes. The proposed incremental learner solves the AT task with an F1 score of 54.4% and the ASC task with an accuracy of 88.9% in an incremental time step, outperforming a multi-task system which solves ASC and AT at the same time. The ASC task performance degrades only by 5.1% from the initial time ASC accuracy of 94.0%.
Evaluating robustness of You Only Hear Once Algorithm on noisy audios in the VOICe Dataset
Nov 01, 2021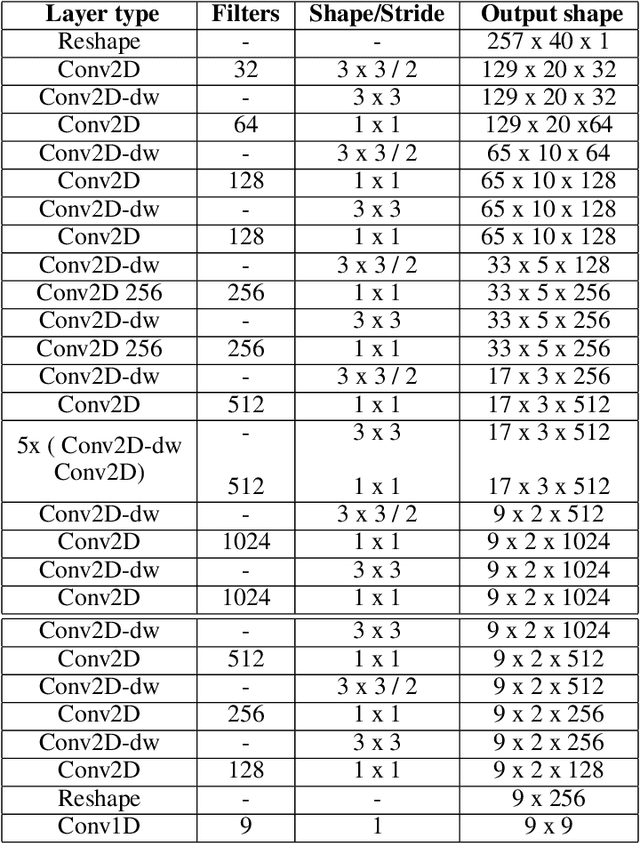
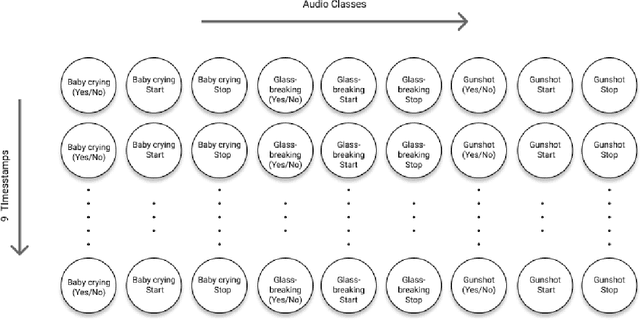
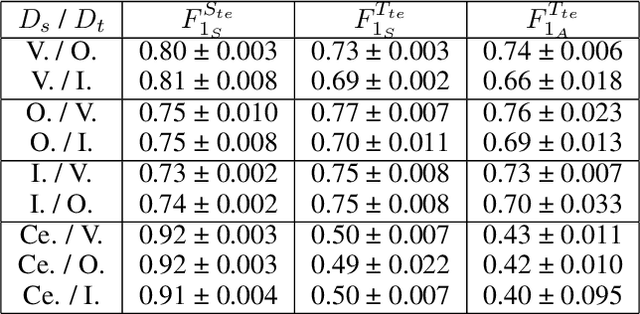
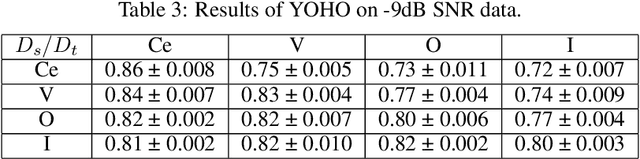
Sound event detection (SED) in machine listening entails identifying the different sounds in an audio file and identifying the start and end time of a particular sound event in the audio. SED finds use in various applications such as audio surveillance, speech recognition, and context-based indexing and retrieval of data in a multimedia database. However, in real-life scenarios, the audios from various sources are seldom devoid of any interfering noise or disturbance. In this paper, we test the performance of the You Only Hear Once (YOHO) algorithm on noisy audio data. Inspired by the You Only Look Once (YOLO) algorithm in computer vision, the YOHO algorithm can match the performance of the various state-of-the-art algorithms on datasets such as Music Speech Detection Dataset, TUT Sound Event, and Urban-SED datasets but at lower inference times. In this paper, we explore the performance of the YOHO algorithm on the VOICe dataset containing audio files with noise at different sound-to-noise ratios (SNR). YOHO could outperform or at least match the best performing SED algorithms reported in the VOICe dataset paper and make inferences in less time.