 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating robustness of You Only Hear Once Algorithm on noisy audios in the VOICe Dataset
Nov 01, 2021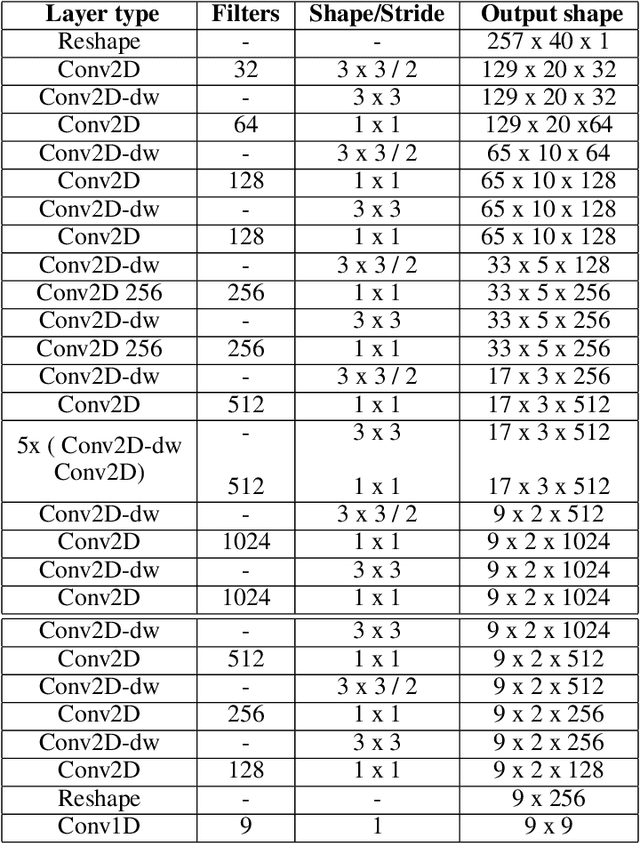
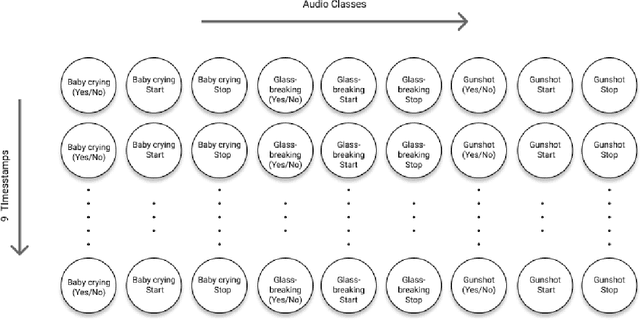
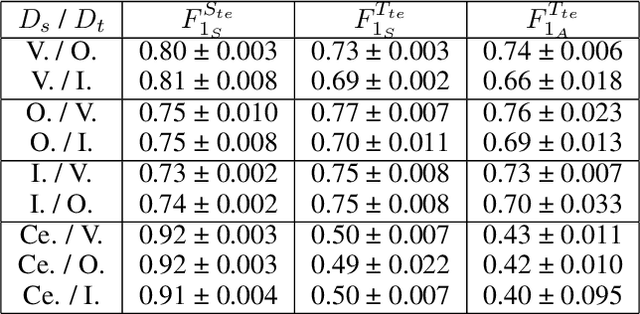
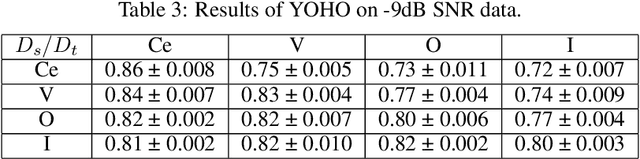
Sound event detection (SED) in machine listening entails identifying the different sounds in an audio file and identifying the start and end time of a particular sound event in the audio. SED finds use in various applications such as audio surveillance, speech recognition, and context-based indexing and retrieval of data in a multimedia database. However, in real-life scenarios, the audios from various sources are seldom devoid of any interfering noise or disturbance. In this paper, we test the performance of the You Only Hear Once (YOHO) algorithm on noisy audio data. Inspired by the You Only Look Once (YOLO) algorithm in computer vision, the YOHO algorithm can match the performance of the various state-of-the-art algorithms on datasets such as Music Speech Detection Dataset, TUT Sound Event, and Urban-SED datasets but at lower inference times. In this paper, we explore the performance of the YOHO algorithm on the VOICe dataset containing audio files with noise at different sound-to-noise ratios (SNR). YOHO could outperform or at least match the best performing SED algorithms reported in the VOICe dataset paper and make inferences in less time.