 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Loop LLM Discovery of Non-Standard Channel Priors in Vision Models
Jan 13, 2026Channel configuration search the optimization of layer specifications such as layer widths in deep neural networks presents a complex combinatorial challenge constrained by tensor shape compatibility and computational budgets. We posit that Large Language Models (LLMs) offer a transformative approach to Neural Architecture Search (NAS), capable of reasoning about architectural code structure in ways that traditional heuristics cannot. In this paper, we investigate the application of an LLM-driven NAS framework to the problem of channel configuration. We formulate the search as a sequence of conditional code generation tasks, where an LLM refines architectural specifications based on performance telemetry. Crucially, we address the data scarcity problem by generating a vast corpus of valid, shape-consistent architectures via Abstract Syntax Tree (AST) mutations. While these mutated networks are not necessarily high-performing, they provide the critical volume of structural data required for the LLM to learn the latent relationship between channel configurations and model performance. This allows the LLM to internalize complex design patterns and apply them to optimize feature extraction strategies. Experimental results on CIFAR-100 validate the efficacy of this approach, demonstrating that the model yields statistically significant improvements in accuracy. Our analysis confirms that the LLM successfully acquires domain-specific architectural priors, distinguishing this method from random search and highlighting the immense potential of language-driven design in deep learning.
From Brute Force to Semantic Insight: Performance-Guided Data Transformation Design with LLMs
Jan 07, 2026Large language models (LLMs) have achieved notable performance in code synthesis; however, data-aware augmentation remains a limiting factor, handled via heuristic design or brute-force approaches. We introduce a performance-aware, closed-loop solution in the NNGPT ecosystem of projects that enables LLMs to autonomously engineer optimal transformations by internalizing empirical performance cues. We fine-tune LLMs with Low-Rank Adaptation on a novel repository of more than 6,000 empirically evaluated PyTorch augmentation functions, each annotated solely by downstream model accuracy. Training uses pairwise performance ordering (better-worse transformations), enabling alignment through empirical feedback without reinforcement learning, reward models, or symbolic objectives. This reduces the need for exhaustive search, achieving up to 600x times fewer evaluated candidates than brute-force discovery while maintaining competitive peak accuracy and shifting generation from random synthesis to task-aligned design. Ablation studies show that structured Chain-of-Thought prompting introduces syntactic noise and degrades performance, whereas direct prompting ensures stable optimization in performance-critical code tasks. Qualitative and quantitative analyses demonstrate that the model internalizes semantic performance cues rather than memorizing syntax. These results show that LLMs can exhibit task-level reasoning through non-textual feedback loops, bypassing explicit symbolic rewards.
From Memorization to Creativity: LLM as a Designer of Novel Neural-Architectures
Jan 06, 2026Large language models (LLMs) excel in program synthesis, yet their ability to autonomously navigate neural architecture design--balancing syntactic reliability, performance, and structural novelty--remains underexplored. We address this by placing a code-oriented LLM within a closed-loop synthesis framework, analyzing its evolution over 22 supervised fine-tuning cycles. The model synthesizes PyTorch convolutional networks which are validated, evaluated via low-fidelity performance signals (single-epoch accuracy), and filtered using a MinHash-Jaccard criterion to prevent structural redundancy. High-performing, novel architectures are converted into prompt-code pairs for iterative fine-tuning via parameter-efficient LoRA adaptation, initialized from the LEMUR dataset. Across cycles, the LLM internalizes empirical architectural priors, becoming a robust generator. The valid generation rate stabilizes at 50.6 percent (peaking at 74.5 percent), while mean first-epoch accuracy rises from 28.06 percent to 50.99 percent, and the fraction of candidates exceeding 40 percent accuracy grows from 2.04 percent to 96.81 percent. Analyses confirm the model moves beyond replicating existing motifs, synthesizing 455 high-performing architectures absent from the original corpus. By grounding code synthesis in execution feedback, this work provides a scalable blueprint for transforming stochastic generators into autonomous, performance-driven neural designers, establishing that LLMs can internalize empirical, non-textual rewards to transcend their training data.
Enhancing LLM-Based Neural Network Generation: Few-Shot Prompting and Efficient Validation for Automated Architecture Design
Dec 30, 2025Automated neural network architecture design remains a significant challenge in computer vision. Task diversity and computational constraints require both effective architectures and efficient search methods. Large Language Models (LLMs) present a promising alternative to computationally intensive Neural Architecture Search (NAS), but their application to architecture generation in computer vision has not been systematically studied, particularly regarding prompt engineering and validation strategies. Building on the task-agnostic NNGPT/LEMUR framework, this work introduces and validates two key contributions for computer vision. First, we present Few-Shot Architecture Prompting (FSAP), the first systematic study of the number of supporting examples (n = 1, 2, 3, 4, 5, 6) for LLM-based architecture generation. We find that using n = 3 examples best balances architectural diversity and context focus for vision tasks. Second, we introduce Whitespace-Normalized Hash Validation, a lightweight deduplication method (less than 1 ms) that provides a 100x speedup over AST parsing and prevents redundant training of duplicate computer vision architectures. In large-scale experiments across seven computer vision benchmarks (MNIST, CIFAR-10, CIFAR-100, CelebA, ImageNette, SVHN, Places365), we generated 1,900 unique architectures. We also introduce a dataset-balanced evaluation methodology to address the challenge of comparing architectures across heterogeneous vision tasks. These contributions provide actionable guidelines for LLM-based architecture search in computer vision and establish rigorous evaluation practices, making automated design more accessible to researchers with limited computational resources.
Preparation of Fractal-Inspired Computational Architectures for Advanced Large Language Model Analysis
Nov 10, 2025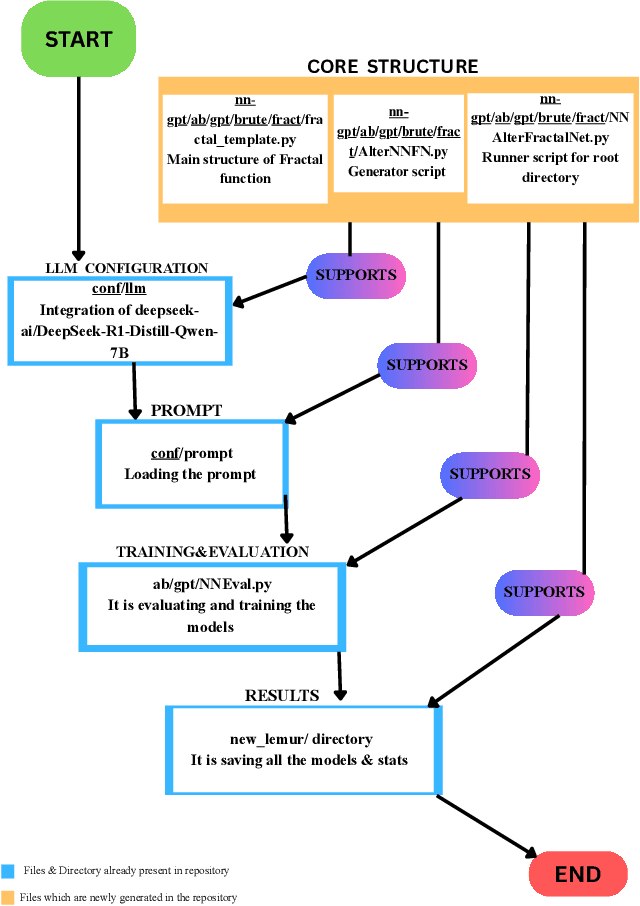



It introduces FractalNet, a fractal-inspired computational architectures for advanced large language model analysis that mainly challenges model diversity on a large scale in an efficient manner. The new set-up involves a template-driven generator, runner, and evaluation framework that, through systematic permutations of convolutional, normalization, activation, and dropout layers, can create more than 1,200 variants of neural networks. Fractal templates allow for structural recursion and multi-column pathways, thus, models become deeper and wider in a balanced way. Training utilizes PyTorch, Automatic Mixed Precision (AMP), and gradient checkpointing and is carried out on the CIFAR-10 dataset for five epochs. The outcomes show that fractal-based architectures are capable of strong performance and are computationally efficient. The paper positions fractal design as a feasible and resource-efficient method of automated architecture exploration.
AugmentGest: Can Random Data Cropping Augmentation Boost Gesture Recognition Performance?
Jun 08, 2025Data augmentation is a crucial technique in deep learning, particularly for tasks with limited dataset diversity, such as skeleton-based datasets. This paper proposes a comprehensive data augmentation framework that integrates geometric transformations, random cropping, rotation, zooming and intensity-based transformations, brightness and contrast adjustments to simulate real-world variations. Random cropping ensures the preservation of spatio-temporal integrity while addressing challenges such as viewpoint bias and occlusions. The augmentation pipeline generates three augmented versions for each sample in addition to the data set sample, thus quadrupling the data set size and enriching the diversity of gesture representations. The proposed augmentation strategy is evaluated on three models: multi-stream e2eET, FPPR point cloud-based hand gesture recognition (HGR), and DD-Network. Experiments are conducted on benchmark datasets including DHG14/28, SHREC'17, and JHMDB. The e2eET model, recognized as the state-of-the-art for hand gesture recognition on DHG14/28 and SHREC'17. The FPPR-PCD model, the second-best performing model on SHREC'17, excels in point cloud-based gesture recognition. DD-Net, a lightweight and efficient architecture for skeleton-based action recognition, is evaluated on SHREC'17 and the Human Motion Data Base (JHMDB). The results underline the effectiveness and versatility of the proposed augmentation strategy, significantly improving model generalization and robustness across diverse datasets and architectures. This framework not only establishes state-of-the-art results on all three evaluated models but also offers a scalable solution to advance HGR and action recognition applications in real-world scenarios. The framework is available at https://github.com/NadaAbodeshish/Random-Cropping-augmentation-HGR
VIST-GPT: Ushering in the Era of Visual Storytelling with LLMs?
Apr 27, 2025Visual storytelling is an interdisciplinary field combining computer vision and natural language processing to generate cohesive narratives from sequences of images. This paper presents a novel approach that leverages recent advancements in multimodal models, specifically adapting transformer-based architectures and large multimodal models, for the visual storytelling task. Leveraging the large-scale Visual Storytelling (VIST) dataset, our VIST-GPT model produces visually grounded, contextually appropriate narratives. We address the limitations of traditional evaluation metrics, such as BLEU, METEOR, ROUGE, and CIDEr, which are not suitable for this task. Instead, we utilize RoViST and GROOVIST, novel reference-free metrics designed to assess visual storytelling, focusing on visual grounding, coherence, and non-redundancy. These metrics provide a more nuanced evaluation of narrative quality, aligning closely with human judgment.
LEMUR Neural Network Dataset: Towards Seamless AutoML
Apr 14, 2025Neural networks are fundamental in artificial intelligence, driving progress in computer vision and natural language processing. High-quality datasets are crucial for their development, and there is growing interest in datasets composed of neural networks themselves to support benchmarking, automated machine learning (AutoML), and model analysis. We introduce LEMUR, an open source dataset of neural network models with well-structured code for diverse architectures across tasks such as object detection, image classification, segmentation, and natural language processing. LEMUR is primarily designed to enable fine-tuning of large language models (LLMs) for AutoML tasks, providing a rich source of structured model representations and associated performance data. Leveraging Python and PyTorch, LEMUR enables seamless extension to new datasets and models while maintaining consistency. It integrates an Optuna-powered framework for evaluation, hyperparameter optimization, statistical analysis, and graphical insights. LEMUR provides an extension that enables models to run efficiently on edge devices, facilitating deployment in resource-constrained environments. Providing tools for model evaluation, preprocessing, and database management, LEMUR supports researchers and practitioners in developing, testing, and analyzing neural networks. Additionally, it offers an API that delivers comprehensive information about neural network models and their complete performance statistics with a single request, which can be used in experiments with code-generating large language models. The LEMUR will be released as an open source project under the MIT license upon acceptance of the paper.
Optuna vs Code Llama: Are LLMs a New Paradigm for Hyperparameter Tuning?
Apr 08, 2025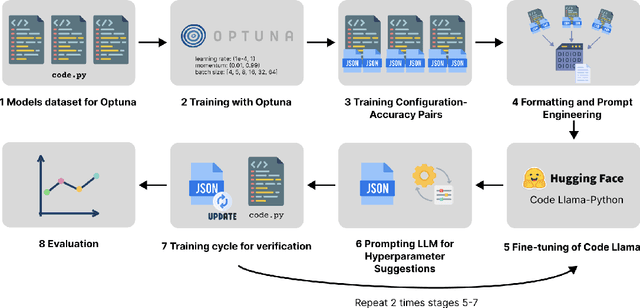



Optimal hyperparameter selection is critical for maximizing neural network performance, especially as models grow in complexity. This work investigates the viability of using large language models (LLMs) for hyperparameter optimization by employing a fine-tuned version of Code Llama. Through parameter-efficient fine-tuning using LoRA, we adapt the LLM to generate accurate and efficient hyperparameter recommendations tailored to diverse neural network architectures. Unlike traditional methods such as Optuna, which rely on exhaustive trials, the proposed approach achieves competitive or superior results in terms of Root Mean Square Error (RMSE) while significantly reducing computational overhead. Our approach highlights that LLM-based optimization not only matches state-of-the-art methods like Tree-structured Parzen Estimators but also accelerates the tuning process. This positions LLMs as a promising alternative to conventional optimization techniques, particularly for rapid experimentation. Furthermore, the ability to generate hyperparameters in a single inference step makes this method particularly well-suited for resource-constrained environments such as edge devices and mobile applications, where computational efficiency is paramount. The results confirm that LLMs, beyond their efficiency, offer substantial time savings and comparable stability, underscoring their value in advancing machine learning workflows. All generated hyperparameters are included in the LEMUR Neural Network (NN) Dataset, which is publicly available and serves as an open-source benchmark for hyperparameter optimization research.
Virtually Enriched NYU Depth V2 Dataset for Monocular Depth Estimation: Do We Need Artificial Augmentation?
Apr 15, 2024We present ANYU, a new virtually augmented version of the NYU depth v2 dataset, designed for monocular depth estimation. In contrast to the well-known approach where full 3D scenes of a virtual world are utilized to generate artificial datasets, ANYU was created by incorporating RGB-D representations of virtual reality objects into the original NYU depth v2 images. We specifically did not match each generated virtual object with an appropriate texture and a suitable location within the real-world image. Instead, an assignment of texture, location, lighting, and other rendering parameters was randomized to maximize a diversity of the training data, and to show that it is randomness that can improve the generalizing ability of a dataset. By conducting extensive experiments with our virtually modified dataset and validating on the original NYU depth v2 and iBims-1 benchmarks, we show that ANYU improves the monocular depth estimation performance and generalization of deep neural networks with considerably different architectures, especially for the current state-of-the-art VPD model. To the best of our knowledge, this is the first work that augments a real-world dataset with randomly generated virtual 3D objects for monocular depth estimation. We make our ANYU dataset publicly available in two training configurations with 10% and 100% additional synthetically enriched RGB-D pairs of training images, respectively, for efficient training and empirical exploration of virtual augmentation at https://github.com/ABrain-One/ANYU